前言
散列表类似于数组,可以把散列表的散列值看成数组的索引值。访问散列表和访问数组元素一样快速,它可以在常数时间内实现查找和插入操作。使用散列的查找算法分为两步:用散列函数将被查找的键转化为数组的一个索引;处理碰撞冲突。
散列函数
要为一个数据类型实现优秀的散列方法需要满足三个条件:
- 一致性:等价的键必然产生相等的散列值。
- 高效性:计算简便。
- 均匀性:均匀的散列所有的键。
对于一致性,在Java中意味着每一种数据类型的hashCode()方法都必须和equals()方法一致。也就是说,如果a.equals(b)返回true,那么a.hashCode()和b.hashCode()的返回值必然相同。但要注意,如果a.hashCode()和b.hashCode()的返回值相同,a.equals(b)不一定返回true。
保证均匀性的最好办法就是保证键的每一位都在散列值的计算中起到了相同的作用,而常见的错误就是忽略了键的高位。在jdk的HashMap中,为了保证均匀性将默认散列函数得到的散列值与其高16位进行异或运算重新得到新的散列值。
为了将一个32位的整数散列值转换成数组的索引,我们在实现中还要将散列值和除留余数法结合起来产生一个0到M-1(M代表数组的大小)的整数。这在HashMap中是通过这行代码实现的:hash & (table.length - 1)。
碰撞处理
基于拉链法的散列表
拉链法是将大小为M的数组中的每个元素指向一条链表,链表中的每个节点都存储了散列值为该元素的索引的键值对。基于拉链法的查找分为两步:首先根据散列值找到对应的链表,然后沿着链表顺序查找相应的键。
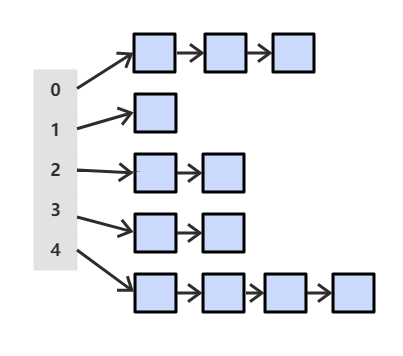
在实现基于拉链法的散列表时,要选择适当的数组大小M,既不会因为空链表而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
基于线性探测法的散列表
实现散列表的另一种方式就是用大小为M的数组保存N个键值对,其中M>N。我们需要依靠数组中的空位解决碰撞冲突,基于这种策略的所有方法被统称为开放地址散列表。
开放地址散列表中最简单的方法叫做线性探测法。我们在实现中使用并行数组,一个保存键,一个保存值。
1 | public class LinearProbingHashST<Key, Value> { |
查找
要查找一个键,我们从它的散列值开始顺序查找,如果找到则命中,否则直接检查散列表中的下一个位置(将索引值加1),直到找到该键或者遇到一个空元素。
1 | public Value get(Key key) { |
插入
如果新建的散列值是一个空元素,那么就将它保存在那里;如果不是,我们就顺序查找一个空元素来保存它。
1 | public void put(Key key, Value val) { |
删除
直接将要删除的键所在的位置设为null是不行的,因为这会使在此位置之后的元素无法被查找。因此,我们需要将簇中被删除键的右侧的所有键重新插入散列表。
1 | public void delete(Key key) { |
为了保证性能,我们会动态调整数组的大小来保证使用率在1/8到1/2之间。
调整数组大小
线性探测法的成本取决于连续条目的长度,连续条目也叫聚簇。当聚簇很长时,在查找和插入时需要进行很多次探测。为了保证散列表的性能,应当动态调整数组的大小,使得散列表的使用率不超过1/2。
1 | private void resize(int capacity) { |
以上实现会将原表中所有的键重新散列并插入到新表中。