前言
排序算法的成本模型计算的是比较和交换的次数。less()方法对元素进行比较,exch()方法将元素交换位置。
1 | private static boolean less(Comparable v, Comparable w) { |
堆的定义
堆的某个节点的值总是大于等于子节点的值,并且堆是一颗完全二叉树。当这棵树的每个结点都大于等于它的两个子节点时,它被称为堆有序。
堆可以用数组来表示,这是因为堆是完全二叉树,而完全二叉树很容易就存储在数组中。位置 k 的节点的父节点位置为 k/2,而它的两个子节点的位置分别为 2k 和 2k+1。
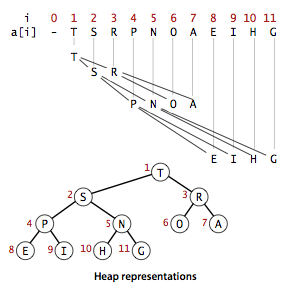
上浮
在堆中,当一个节点比父节点大,那么需要交换这个两个节点。交换后还可能比它新的父节点大,因此需要不断地进行比较和交换操作,把这种操作称为上浮。
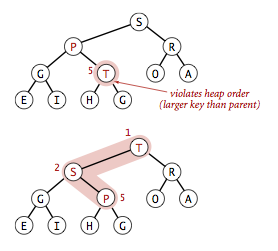
实现如下:
1 | private void swim(int k) { |
下沉
在堆中,当一个节点比子节点小,需要不断地向下进行比较和交换操作,把这种操作称为下沉。一个节点如果有两个子节点,应当与两个子节点中最大那个节点进行交换。
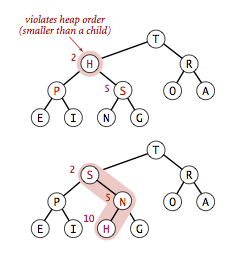
实现如下:
1 | private void sink(int k) { |
堆排序
堆排序可以分为两个阶段。在堆的构造阶段中,我们将原始数组重新组织安排进一个堆中;然后在下沉排序阶段,我们从堆中按递减顺序取出所有元素并得到排序结果。
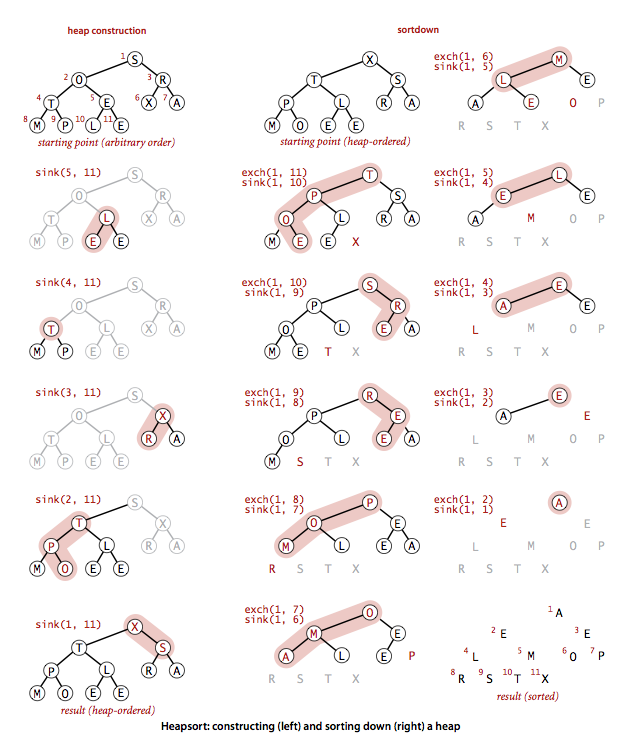
堆的构造
无序数组建立堆最直接的方法是从左到右遍历数组进行上浮操作。一个更高效的方法是从右至左进行下沉操作,如果一个节点的两个节点都已经是堆有序,那么进行下沉操作可以使得这个节点为根节点的堆有序。叶子节点不需要进行下沉操作,可以忽略叶子节点的元素,因此只需要遍历一半的元素即可。
下沉排序
堆排序的主要工作都是在这一阶段完成的。这里我们将堆中的最大元素删除,然后放入堆缩小后数组中空出的位置。
1 | public class Heap { |
复杂度分析
一个堆的高度为 logN,因此在堆中插入元素和删除最大元素的复杂度都为 logN。
对于堆排序,由于要对 N 个节点进行下沉操作,因此复杂度为 NlogN。
现代系统的许多应用很少使用它,因为它无法利用缓存。数组元素很少和相邻的其它元素进行比较,因此无法利用局部性原理,缓存未命中的次数很高。
- 最坏时间复杂度 О(nlogn)
- 最优时间复杂度 O(nlogn)
- 平均时间复杂度 O(nlogn)
- 空间复杂度 O(1)
- 不稳定