优化数据访问
减少请求的数据量
- 只返回必要的行:使用
LIMIT语句来限制返回的数据。 - 只返回必要的列:最好不要使用
SELECT *语句。 - 缓存重复查询的数据。
减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
重构查询方式
切分查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。因此可以将大查询切分成小查询,每个查询功能完全一样,只完成一小部分,每次只返回一小部分查询结果。
分解关联查询
可以对每一个表进行一次单表查询,然后将结果在应用程序中进行关联。这么做有如下优势:
- 让缓存的效率更高。对于关联查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
- 将查询分解后,执行单个查询可以减少锁的竞争。
- 分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
查询执行
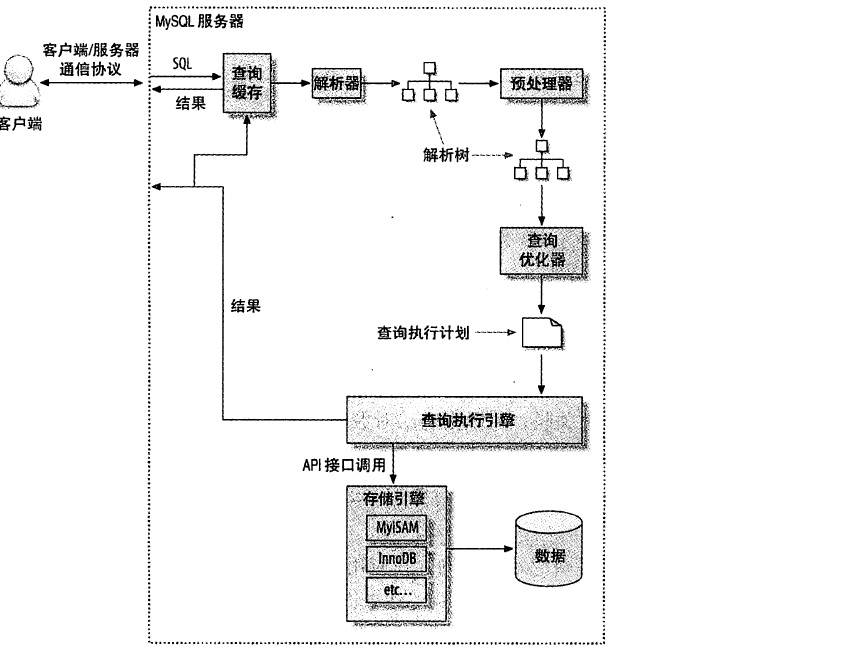
- 客户端发送一条查询给服务器。
- 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段。
- 服务器端进行SQL解析、预处理再由优化器生成对应的执行计划。
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询。
- 将结果返回给客户端。
MySQL解析器将使用MySQL语法规则验证和解析查询;预处理器则根据一些MySQL规则进一步检查解析树是否合法,例如检查数据表和数据列是否存在,之后会验证权限;查询优化器的作用是根据存储引擎提供的统计信息找出一个最优的执行计划。
优化 Limit 分页
在偏移量特别大的时候,例如可能是LIMIT 1000, 20这样的查询,这时MySQL需要查询10020条记录然后只返回最后20条,前面10000条记录都将被抛弃,这样的代价非常高。可以通过延迟关联和书签两个技巧进行优化。
延迟关联
优化此类分页查询的一个最简单的办法就是尽可能地使用索引覆盖扫描,而不是查询所有的列。然后根据需要做一次关联操作再返回所需的列。考虑下面的查询:
1 | SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 50, 5; |
此时没有覆盖索引,因此要回表获取记录55条,而只返回最后5条。这时候可以用延迟关联的技巧改写成如下:
1 | SELECT film.film_id, film.description |
这时候子查询中能使用覆盖索引,因此在索引结构中就能获取到需要访问的记录而无需回表,之后再根据关联列回表查询需要的所有列。
书签
LIMIT和OFFSET的问题,其实是OFFSET的问题,它会导致MySQL扫描大量不需要的行然后再抛弃掉。如果可以使用书签记录上次取数据的位置,那么下次就可以直接从该书签记录的位置开始扫描,这样就可以避免使用OFFSET。例如,若需要按照租借记录做翻页,那么可以根据最新一条租借记录向后追溯,首先使用下面的查询获得第一组结果:
1 | SELECT * FROM sakila.rental |
会返回49到30的记录,那么下一页查询就可以从30这个点开始:
1 | SELECT * FROM sakila.rental |
该技术的好处是无论翻页到多么后面,其性能都会很好。
参考资料
- 高性能 MySQL[M]. 电子工业出版社, 2013.
- CS-Notes