地址重定位
为了保证CPU执行指令时可正确访问内存单元,需要将用户程序中的逻辑地址转换为运行时可由机器直接寻址的物理地址,这一过程称为地址重定位(又称地址转换、地址变换、地址翻译、地址映射)。
- 逻辑地址(相对地址,虚拟地址):目标代码通常采用相对地址的形式,其首地址为0, 其余地址都相对于首地址而编址。不能用逻辑地址在内存中读取信息。
- 物理地址(绝对地址,实地址):内存中存储单元的地址,可直接寻址。
地址重定位分为静态重定位和动态重定位:
- 静态重定位:当用户程序加载到内存时,一次性实现逻辑地址到物理地址的转换。
- 动态重定位:在进程执行过程中进行地址变换,即逐条指令执行时完成地址转换。
伙伴系统
Linux底层内存管理采用伙伴系统这一种经典的内存分配方案。
主要思想:将内存按2的幂进行划分,组成若干空闲块链表;查找该链表找到能满足进程需求的最佳匹配块。
过程:
- 首先将整个可用空间看作一块: 2^u
- 假设进程申请的空间大小为 s,如果满足 2^u-1 < s <= 2^u,则分配整个块;否则,将块划分为两个大小相等的伙伴,大小为2^u-1
- 一直划分下去直到产生大于或等于 s 的最小块
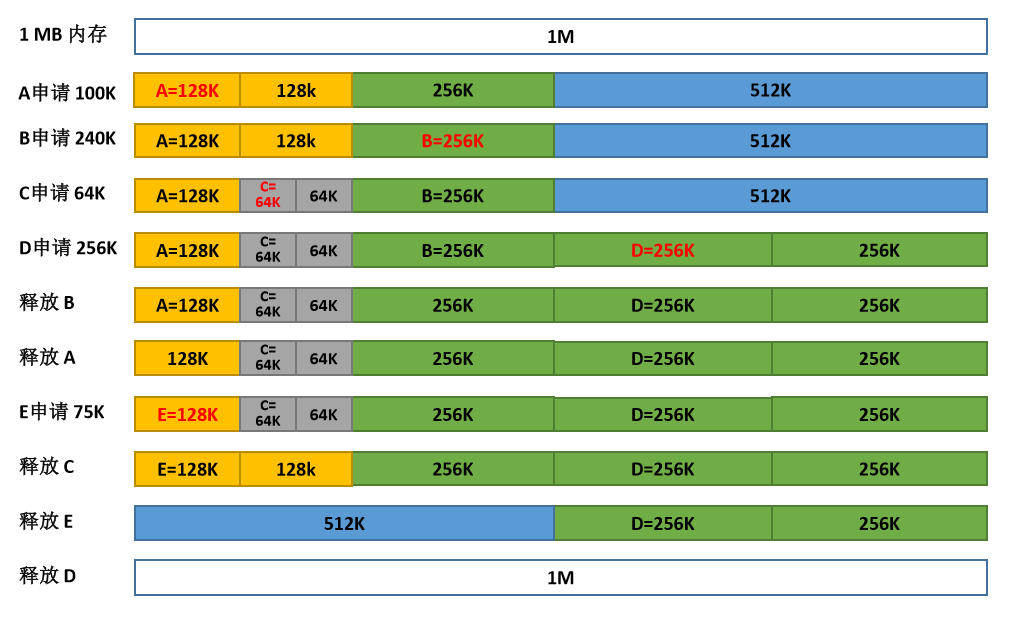
基本内存管理方案一
整个进程进入内存中一片连续区域。
单一连续区
内存在此方式下分为系统区和用户区,系统区仅提供给操作系统使用,用户区是为用户提供的、除系统区之外的内存空间。一段时间内只有一个进程在内存,简单但内存利用率低。
固定分区
把内存空间分割成若干区域,称为分区,每个分区的大小可以相同也可以不同,但分区大小固定不变,每个分区装一个且只能装一个进程。
这种方式会产生两个问题:一是程序太大而放不进任何一个分区中;二是容易产生内部碎片。
可变分区
可变分区是一种动态划分内存的分区方法。这种分区方法不预先将内存划分,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。因此系统中分区的大小和数目是可变的。
可变分区虽然不会产生内部碎片,但容易产生外部碎片,导致内存利用率下降。
在进程装入或换入主存时,如果内存中有多个足够大的空闲块,操作系统必须确定分配哪个内存块给进程使用,考虑以下几种分配算法:
- 首次适配(first fit):在空闲区表中找到第一个满足进程要求的空闲区。该算法优先使用低址部分空闲区,在低址空间造成许多小的空闲区,在高地址空间保留大的空闲区。
- 下次适配(next fit):从上次找到的空闲区处接着查找。
- 最佳适配(best fit):查找整个空闲区表,找到能够满足进程要求的最小空闲区。该算法保留大的空闲区,但造成许多小的空闲区。
- 最差适配(worst fit ):总是分配满足进程要求的最大空闲区。该算法保留小的空闲区,尽量减少小的碎片产生。
基本内存管理方案二
一个进程进入内存中若干片不连续的区域。
页式存储管理方案
用户进程地址空间被划分为大小相等的部分,称为页(page)或页面,从0开始编号。内存空间按同样大小划分为大小相等的区域,称为页框(page frame)或物理页面或内存块,从0开始编号。
内存分配规则:以页为单位进行分配,并按进程需要的页数来分配;逻辑上相邻的页,物理上不一定相邻。
每个进程一个页表,存放在内存。
地址转换
CPU取到逻辑地址,自动划分为页号和页内地址;用页号查页表,得到页框号,再与页内偏移拼接成为物理地址。
段式存储管理方案
将用户进程地址空间按程序自身的逻辑关系划分为若干个程序段,每个程序段都有一个段号。内存空间被动态划分为若干长度不相同的区域, 称为物理段,每个物理段由起始地址和长度确定。
内存分配规则:以段为单位进行分配,每段在内存中占据连续空间,但各段之间可以不相邻。
地址转换
CPU取到逻辑地址,自动划分为段号和段内地址;用段号查段表,得到该段在内存的起始地址,与段内偏移地址计算出物理地址。
覆盖技术
把一个程序划分为一系列功能相对独立的程序段,让执行时不要求同时装入内存的程序段组成一组(称为覆盖段),共享同一块内存区域 ,这种内存扩充技术就是覆盖技术。
程序段先保存在磁盘上,当有关程序段的前一部分执行结束,把后续程序段调入内存,覆盖前面的程序段。
一般要求作业各模块之间有明确的调用结构,程序员要向系统指明覆盖结构,然后由操作系统完成自动覆盖。
交换技术
内存空间紧张时,系统将内存中某些进程暂时移到外存,把外存中某些进程换进内存,占据前者所占用的区域(进程在内存与磁盘之间的动态调度)。
虚拟存储技术
所谓虚拟存储技术是指:当进程运行时,先将其一部分装入内存,另一部分暂留在磁盘,当要执行的指令或访问的数据不在内存时,由操作系统自动完成将它们从磁盘调入内存的工作。
- 虚拟地址空间:分配给进程的虚拟内存
- 虚拟地址:在虚拟内存中指令或数据的位置, 该位置可以被访问,仿佛它是内存的一部分
- 虚拟内存:把内存与磁盘有机地结合起来使用,从而得到一个容量很大的“内存”
虚拟页式存储管理系统
虚拟页式即将虚拟存储技术和页式存储管理方案结合起来,以CPU时间和磁盘空间换取昂贵内存空间。
基本思想:进程开始运行之前,不是装入全部页面, 而是装入一个或零个页面,之后,根据进程运行的需要,动态装入其他页面。当内存空间已满,而又需要装入新的页面时,则根据某种算法置换内存中的某个页面,以便装入新的页面。
内存管理单元(MMU)
内存管理单元(MMU)管理着地址空间和物理内存的转换,其中的页表(Page table)存储着页(程序地址空间)和页框(物理内存空间)的映射表。
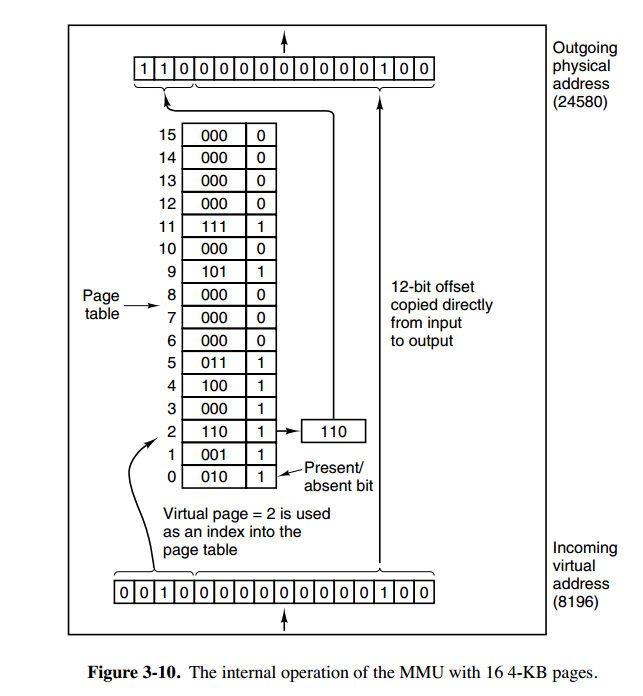
上图为一级页表结构的地址转换,下图为二级页表结构的地址转换及MMU的位置。
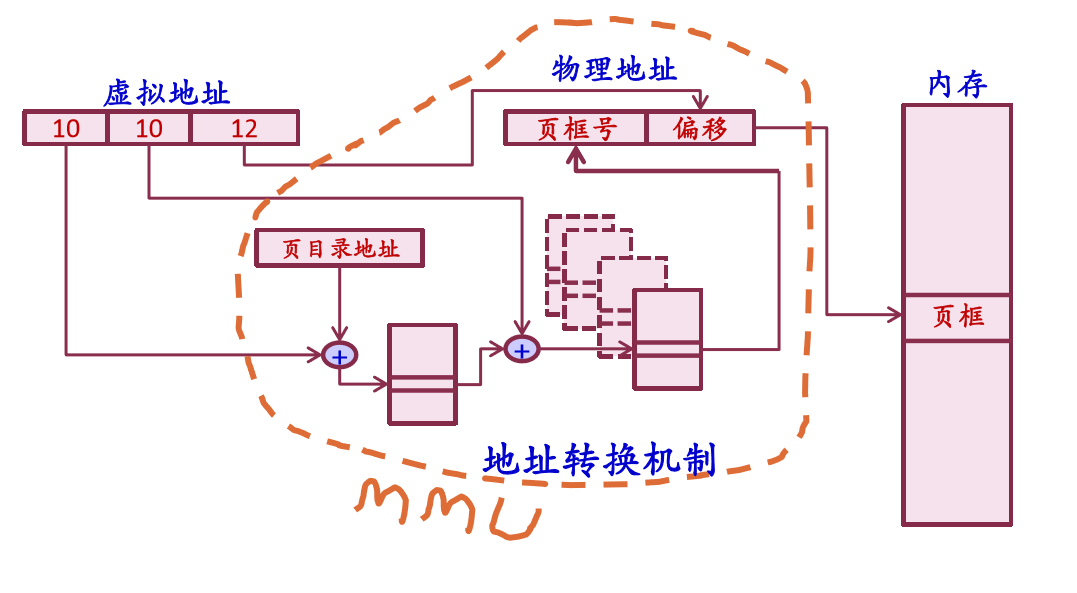
二级页表结构及地址映射
页目录表共有2^10 = 1K个表项,每个表项是4B,因此页目录大小为4K,存储在一个4K字节的页面中。同理,一个页表也存储在一个4K字节的页面中。
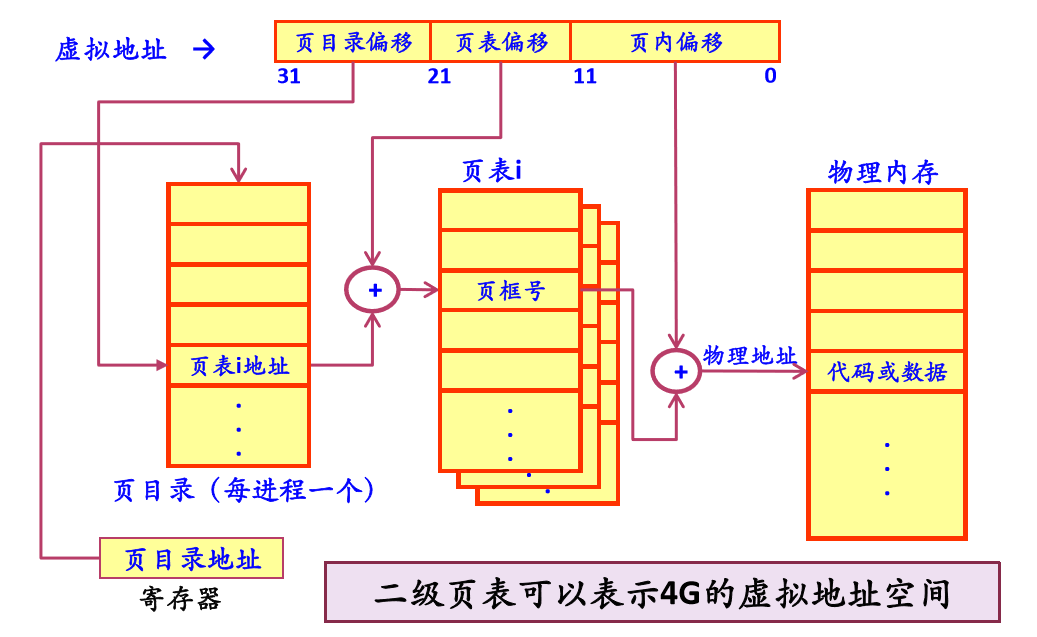
为什么要使用多级页表
系统分配给每个进程的虚拟地址都是4G,那么采用一级页表需要4G/4K = 2^20个表项,如果每个页表项是4B,那么需要4MB的内存空间。但是大多数程序根本用不到4G的虚拟内存空间,比如hello world程序,这样一个几kb的程序却需要4MB的内存空间是很浪费的。如果采用二级页表,那么一级页表只需要4KB的空间用来索引二级页表的地址,像hello world这样的程序可能只需要一个物理页,那么只需要一条记录就可以了,故对于二级页表也只要4KB就足够了,所以这样只需要8KB就能解决问题。
TLB(快表)
页表一般都很大,并且存放在内存中,所以处理器引入MMU后,读取指令、数据需要访问两次内存:首先通过查询页表得到物理地址,然后访问该物理地址读取指令、数据。由于CPU的指令处理速度与内存指令的访问速度差异大,CPU的速度得不到充分利用,为了减少因为MMU导致的处理器性能下降,引入了TLB。
TLB(Translation Lookaside Buffer)转换检测缓冲区相当于页表的缓存,利用程序访问的局部性原理改进虚拟地址到物理地址的转换速度。TLB保存正在运行进程的页表的子集(部分页表项),只有在TLB无法完成地址转换任务时,才会到内存中查询页表,这样就减少了页表查询导致的处理器性能下降。
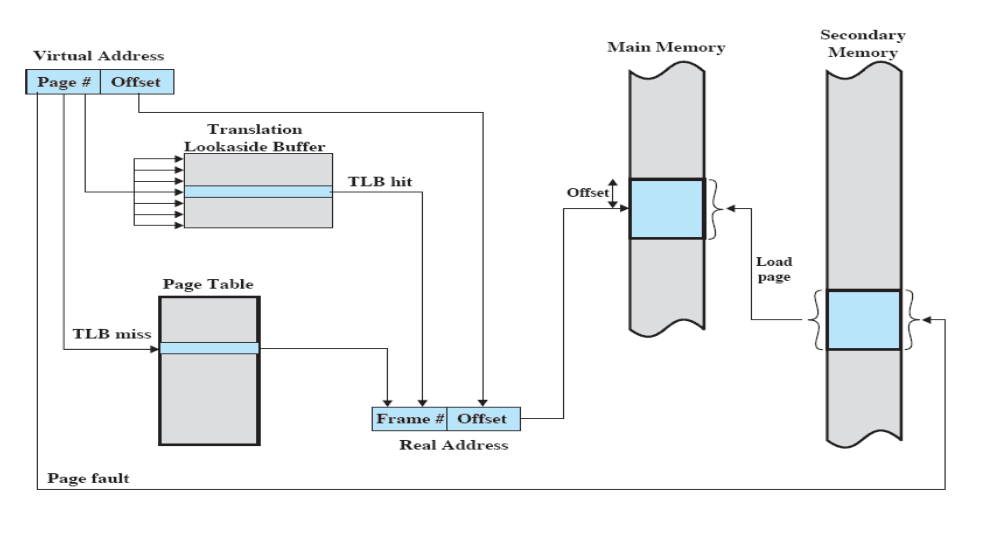
缺页异常
缺页异常是一种Page Fault(页错误)。在地址映射过程中,硬件检查页表时发现所要访问的页面不在内存,则产生缺页异常,操作系统执行缺页异常处理程序:获得磁盘地址,启动磁盘,将该页调入内存。此时分为两种情况:
- 如果内存中有空闲页框,则分配一个页框, 将新调入页装入,并修改页表中相应页表项的有效位及相应的页框号。
- 若内存中没有空闲页框,则要置换内存中某一页框;若该页框内容被修改过,则要将其写回磁盘。
页面置换算法
最佳页面置换算法(OPT,Optimal)
置换以后不再需要的或最远的将来才会用到的页面。
这是一种理论上的算法,因为无法知道一个页面多长时间不再被访问,它作为一种标准来衡量其他算法的性能。
先进先出算法(FIFO)
选择在内存中驻留时间最长的页并置换它。
该算法会将那些经常被访问的页面也被换出,从而使缺页率升高。
第二次机会算法(SCR,Second Chance)
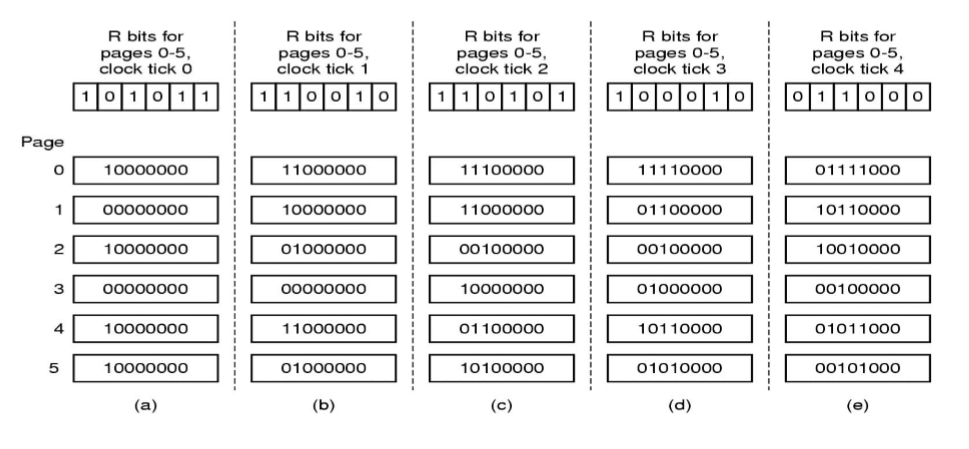
当页面被访问 (读或写) 时设置该页面的R位为1。需要替换的时候,检查最老页面的R位。如果R位是0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是1,就将R位清0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。
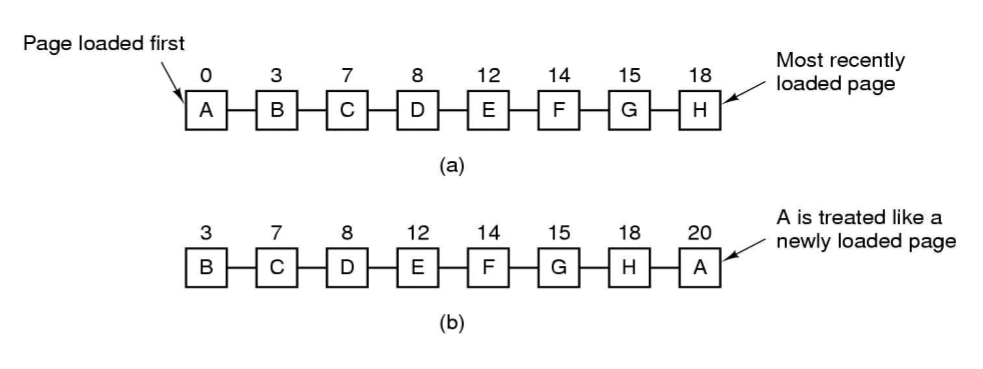
这个算法是对FIFO算法的改进,不会像FIFO一样把经常使用的页面置换出去。
时钟算法(CLOCK)
第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。
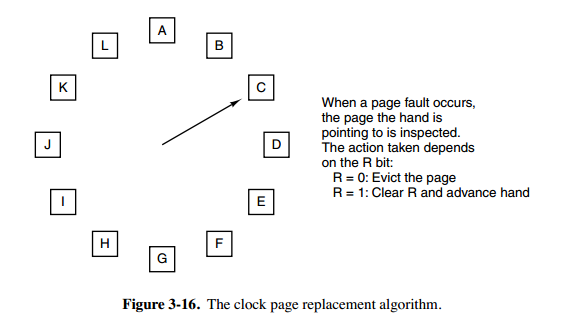
最近未使用算法(NRU,Not Recently Used)
选择在最近一段时间内未使用过的一页并置换。
每个页面都有两个状态位:R与M,当页面被访问时设置页面的R=1,当页面被修改时设置M=1。其中R位会定时被清零。可以将页面分成以下四类:
- R=0,M=0
- R=0,M=1
- R=1,M=0
- R=1,M=1
当发生缺页中断时,NRU算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU算法优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
最近最久未使用算法(LRU,Least Recently Used )
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU算法选择最后一次访问时间距离当前时间最长的一页并置换,即置换未使用时间最长的一页。
为了实现LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最长时间未访问的。
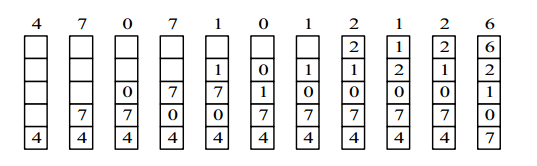
LRU的性能接近OPT,但因为每次访问都需要更新链表,因此这种方式实现的LRU代价很高。
最不经常使用算法(NFU,Not Frequently Used)
NFU算法选择访问次数最少的页面置换。
因为LRU算法的实现比较麻烦而且开销很大,所以提出了用软件来模拟LRU算法的NFU算法,该算法为每一页设置一个软件计数器,初值为0,每次时钟中断的时候就将计数器加R,发生缺页中断时选择计数器值最小的一页置换。
老化算法(AGING)
在NFU算法中存在一个问题:在第一次时钟中断的时候其中一页可能被访问了很多次,之后再未被访问过,然而在以后的时钟中断这一页计数器的值仍然高于其它页,因此其虽然长时间未被访问也不会被置换出去。
为了更好地模拟LRU算法,老化算法对NFU进行了改进,计数器在加R前先右移一位,R位加到计数器的最左端。
工作集算法
基本思想:根据程序的局部性原理,一般情况下,进程在一段时间内总是集中访问一些页面,这些页面称为活跃页面,如果分配给一个进程的物理页面数太少了,使该进程所需的活跃页面不能全部装入内存,则进程在运行过程中将频繁发生中断 。如果能为进程提供与活跃页面数相等的物理页 面数,则可减少缺页中断次数。
工作集W(t, Δ) = 该进程在过去的Δ个虚拟时间单位中访问到的页面的集合
工作集算法就是找出一个不在工作集中的页面并置换它。具体过程为:扫描所有页表项,如果一个页面的R位是1,则将该页面的最后一次访问时间设为当前时间,将R位清零;如果一个页面的R位是0,则检查该页面的访问 时间是否在“当前时间-T”之前,如果是,则该页面为被置换的页面;如果不是,记录当前所有被扫描过页面的最后访问时间里面的最小值,扫描下一个页面并重复上述过程。
参考资料
- Tanenbaum A S, Bos H. Modern operating systems[M]. Prentice Hall Press, 2014.
- 北京大学操作系统原理(Operating Systems)
- 计算机操作系统
- 内存连续分配方式的几种算法及优劣
- 多级页表