为什么要使用ConcurrentHashMap
HashMap线程不安全。在JDK1.8之前的版本中,HashMap的实现在并发执行put操作时会导致HashMap的
Entry链表形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。在之后的版本中这个死循环的问题不再发生,但仍然无法保证并发环境下的线程安全。HashTable使用
synchronized来保证线程安全,因此当一个线程访问HashTable的同步方法时,其它线程也访问同步方法就会被阻塞,在线程竞争激烈时效率很低。
基于以上两点,我们在并发环境中应该选择线程安全且高效的ConcurrentHashMap。
版本演进
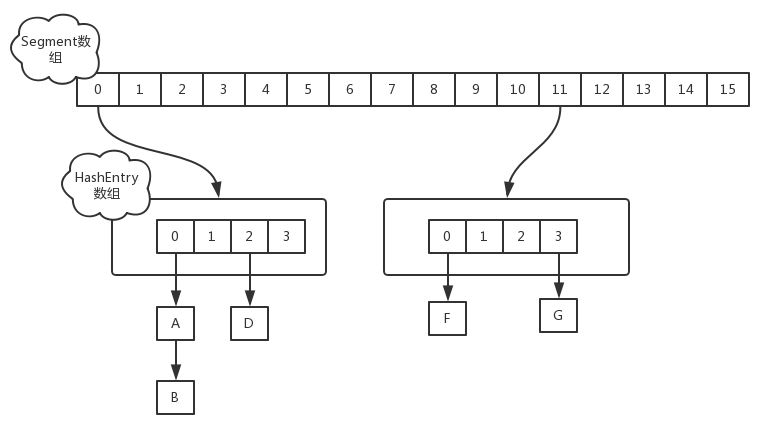
- jdk1.7采用分段锁技术,整个哈希表被分成多个段,每个段中会对应一个Segment段锁,段与段之间可以并发访问,但是多线程想要操作同一个段是需要获取锁的。所有的put,get,remove等方法都是根据键的哈希值对应到相应的段中,然后尝试获取锁进行访问。
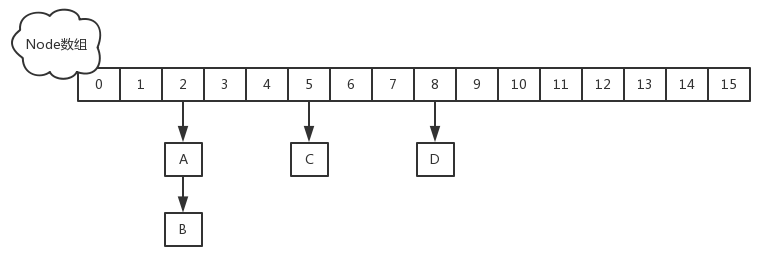
- jdk1.8取消了基于Segment的分段锁思想,改用CAS + synchronized控制并发操作,在某些方面提升了性能。并且追随1.8版本的 HashMap 底层实现,使用数组+链表+红黑树进行数据存储。
JDK1.8分析
属性
1 | transient volatile Node<K,V>[] table; //哈希表,第一次put时才进行初始化 |
ForwardingNode
这是一个特殊的Node节点,用来占位表示扩容时该桶的所有节点已完成迁移,hash值为-1,key和value都为null,并且内部存储着扩容后的表nextTable的引用。
1 | final class ForwardingNode<K,V> extends Node<K,V> { |
put()
在计算键所对应的哈希值后,如果哈希表还未初始化,那么初始化它。此时只允许一个线程对表进行初始化,如果不巧有其他线程进来了,那么会让其他线程交出CPU等待下次系统调度。
初始化完后,获取table中对应索引的元素f,如果f为null,说明table中这个位置第一次插入元素,利用
Unsafe.compareAndSwapObject方法插入Node节点。如果CAS成功,说明Node节点已经插入,随后addCount()方法会检查当前容量是否需要进行扩容。如果CAS失败,说明有其它线程提前插入了节点,自旋重新尝试在这个位置插入节点。如果f的hash值等于
MOVED也就是-1时,说明当前f是ForwardingNode节点,意味着有其它线程正在扩容,于是调用helpTransfer()方法让当前线程去协助扩容。其余情况把新的Node节点按链表或红黑树的方式插入到合适的位置,这个过程采用同步内置锁实现并发。
transfer()
ConcurrentHashMap的扩容是高度并发的,执行逻辑如下:
通过计算CPU核心数和Map数组的长度得到每个线程要帮助处理多少个桶,并且这里每个线程处理都是平均的。默认每个线程处理16个桶,因此,当长度是16的时候,扩容的时候只会有一个线程扩容。
初始化
nextTable,将其在原有基础上扩容两倍。进入一个while循环,每个线程会先领取自己的任务区间,然后开始
--i来遍历自己的任务区间,对每个桶进行处理。如果遇到桶的头结点是空的,那么使用
ForwardingNode标识该桶已经被处理完成了。如果遇到已经处理完成的桶,直接跳过进行下一个桶的处理。如果是正常的桶,对桶首节点加锁,正常的迁移即可,迁移结束后依然会将原表的该位置标识位已经处理。finnish如果为true 则说明整张表的迁移操作已经全部完成了,我们只需要重置table的引用并将nextTable赋为空即可。否则,CAS式的将sizeCtl减一,表示当前线程已经完成了任务,退出扩容操作。
addCount()
当我们成功的添加完成一个结点,最后是需要判断添加操作后是否会导致哈希表达到它的阈值,并针对不同情况决定是否需要进行扩容,还有CAS式更新哈希表实际存储的键值对数量,这些操作都封装在addCount这个方法中,当然putVal方法的最后必然会调用该方法进行处理。该方法主要做两个事情:一是更新 baseCount,二是判断是否需要扩容。
remove()
ConcurrentHashMap的并发删除过程:首先遍历整张表的桶结点,如果表还未初始化或者无法根据参数的哈希值定位到桶结点,那么将返回null。如果定位到的桶结点类型是ForwardingNode结点,调用helpTransfer协助扩容。否则给桶加锁,删除一个节点,最后调用addCount()方法CAS式更新baseCount的值。