锁的种类
在数据库中经常能听到各种各样的锁,比如说悲观锁、乐观锁、行锁、表锁等等,但实际上前两者是从思想上进行划分的,而后两者是从锁粒度上进行划分的,真正的锁有共享锁和排他锁,也就是常说的读锁(S锁)和写锁(X锁)。
封锁协议
在运用X锁和S锁对数据对象进行加锁时,还需要约定一些规则,例如何时申请X锁或S锁、持锁时间、何时释放等,这些规则称为封锁协议,对封锁方式规定不同的规则,就形成了各种不同的封锁协议。
一级封锁协议
一级封锁协议即事务在修改某行数据时必须先对其加X锁,直到事务结束才释放,事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。一级封锁协议可以防止丢失修改,因为此时别的事务要想修改该数据将会阻塞到对方释放X锁,但如果仅仅是读数据不对其进行修改,是不需要加锁的,也就不能保证可重复读和脏读问题。
二级封锁协议
二级封锁协议即在一级封锁协议的基础上,事务读取某数据之前必须先对其加S锁,读完后即可释放S锁。二级封锁协议除了防止丢失修改,还可以进一步防止脏读问题,但在二级封锁协议中,由于读完数据后即可释放S锁,所以它不能保证可重复读。
三级封锁协议
三级封锁协议即在一级封锁协议的基础上,事务读取某数据之前必须先对其加S锁,直到事务结束才释放。三级封锁协议除了防止丢失修改和脏读问题以外,还进一步防止了不可重复读。
两段锁协议
一次性锁协议指的是在事务开始时,一次性申请所有的锁,之后不会再申请任何锁,如果其中某个锁不可用,则整个申请就不成功,事务就不会执行,一次性释放所有的锁。一次性锁协议不会产生死锁的问题,但事务的并发度不高。
InnoDB遵循的是两段锁协议,将事务分成两个阶段,加锁阶段和解锁阶段(所以叫两段锁):
- 加锁阶段:事务只能加锁,也可以操作数据,但不能解锁,直到事务释放第一个锁,就进入解锁阶段
- 解锁阶段:事务只能解锁,也可以操作数据,但不能加锁
两段锁协议使得事务具有较高的并发度,但是没有解决死锁的问题,因为它在加锁阶段没有顺序要求,如两个事务分别申请了A、B锁,接着又申请了对方的锁,此时进入死锁状态。
多版本并发控制(MVCC)
为了提高并发性能,让读写之间能不用相互阻塞,InnoDB实现了MVCC,不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能。
redo/undo log
为了支持事务,InnoDB实现了redo log与undo log:
- redo log:保存执行的sql语句到一个指定的log文件,当MySQL执行recovery时重新执行redo log记录的sql操作即可,当客户端执行每条sql时,redo log首先会被写入log buffer,当客户端执行COMMIT时,log buffer中的内容会被视情况刷新到磁盘。redo log在磁盘上作为一个独立的文件存在,即InnoDB的log文件。
- undo log:与redo log相反,undo log是为回滚而用,把该行修改前的值copy到undo buffer,在适合的时间把undo buffer中的内容刷新到磁盘。与redo log不同的是,磁盘上不存在单独的undo log文件,所有的undo log均存放在.ibd数据文件中。
隐藏字段
在MySQL中,InnoDB为每行记录都实现了三个隐藏字段:
- 6字节的
DB_TRX_ID:事务ID,每处理一个事务,其值自动+1 - 7字节的
DATA_ROLL_PTR:回滚指针,指向该行修改前的上一个历史版本 - 6字节的
DB_ROW_ID:如果表中没有显示定义主键或者没有唯一非空索引时InnoDB会自动创建
当插入一条新数据时,记录上对应的回滚指针为null:
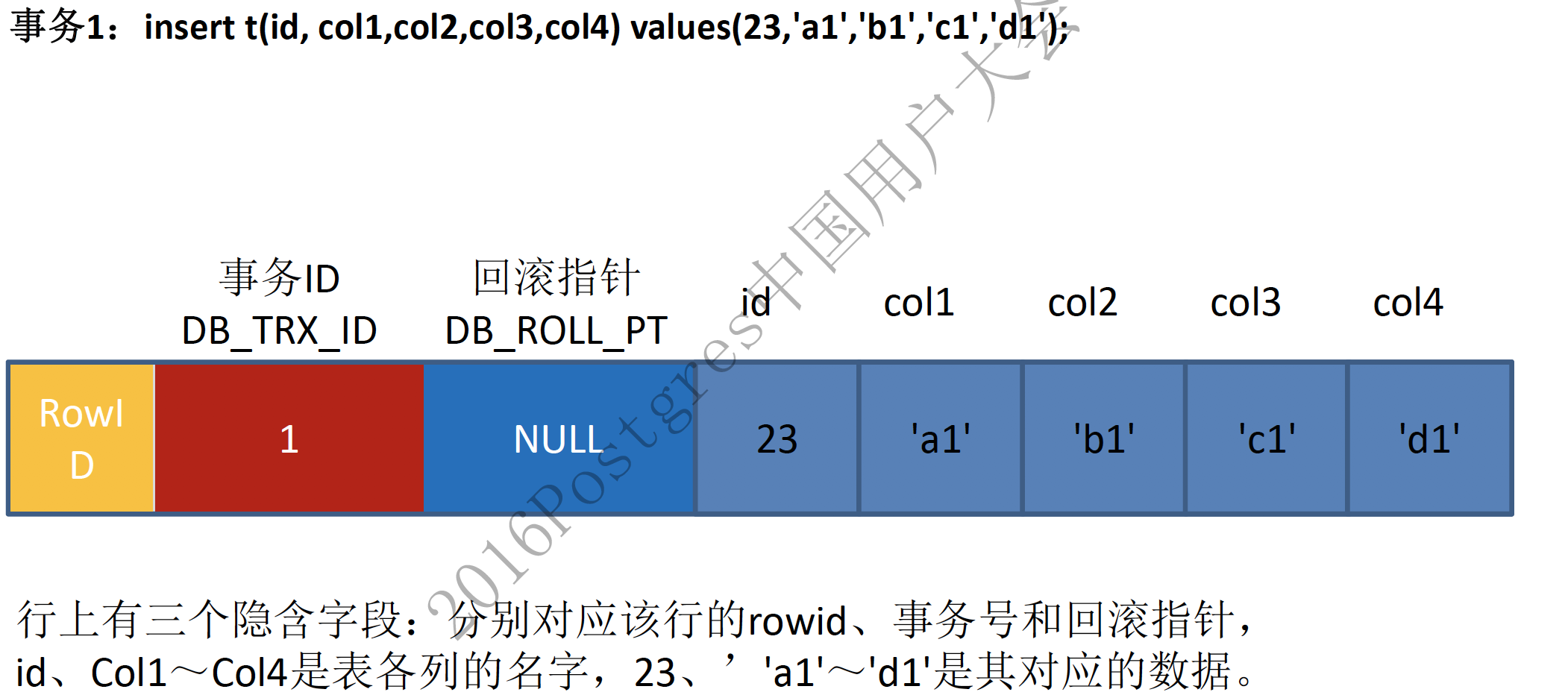
更新记录时,原记录将被放入到undo log中,并通过DATA_ROLL_PT指向该记录:
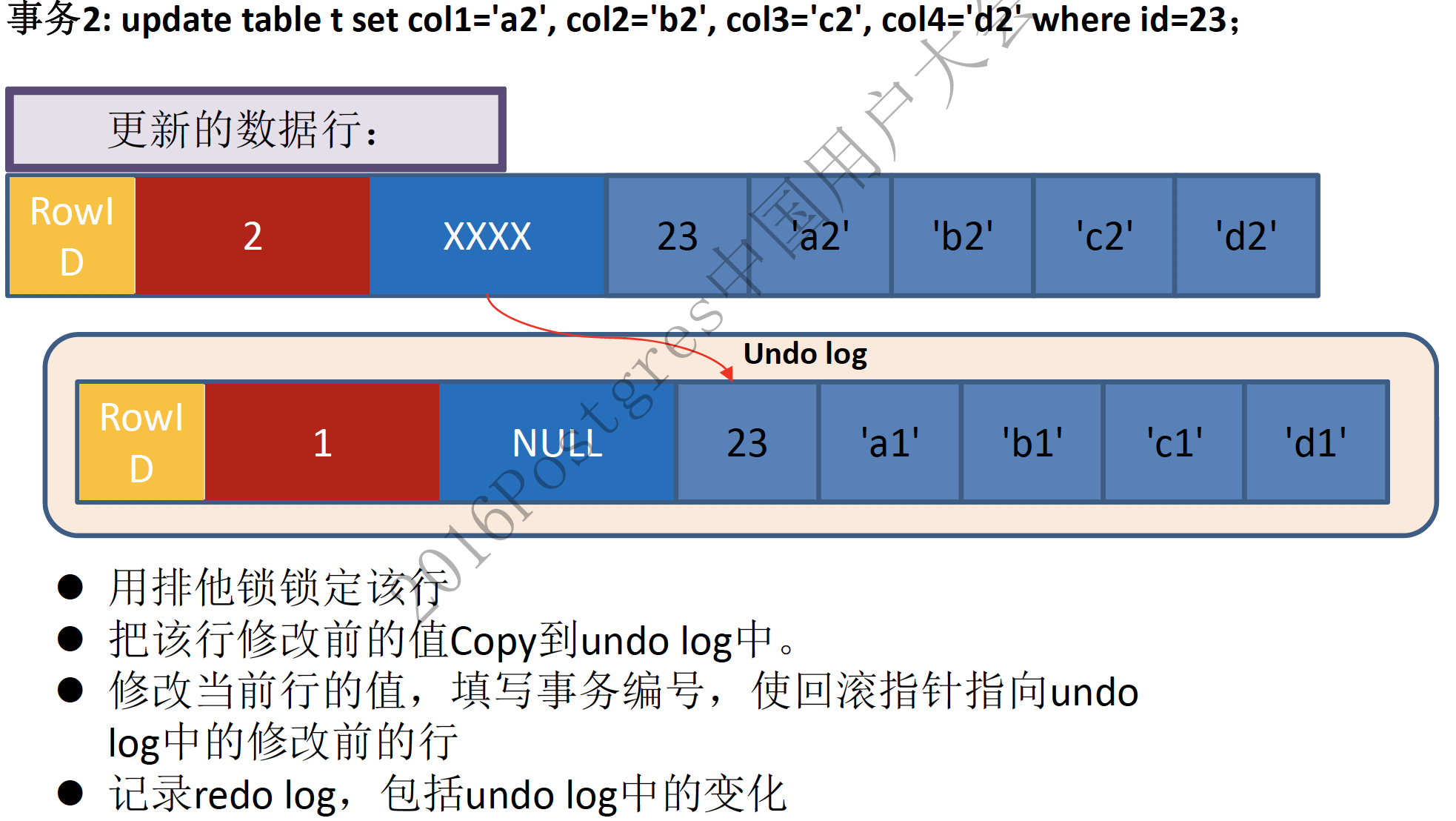
MySQL就是根据记录上的回滚指针及事务ID判断记录是否可见,如果不可见则按照DATA_ROLL_PT继续回溯查找。
通过read view判断行记录是否可见
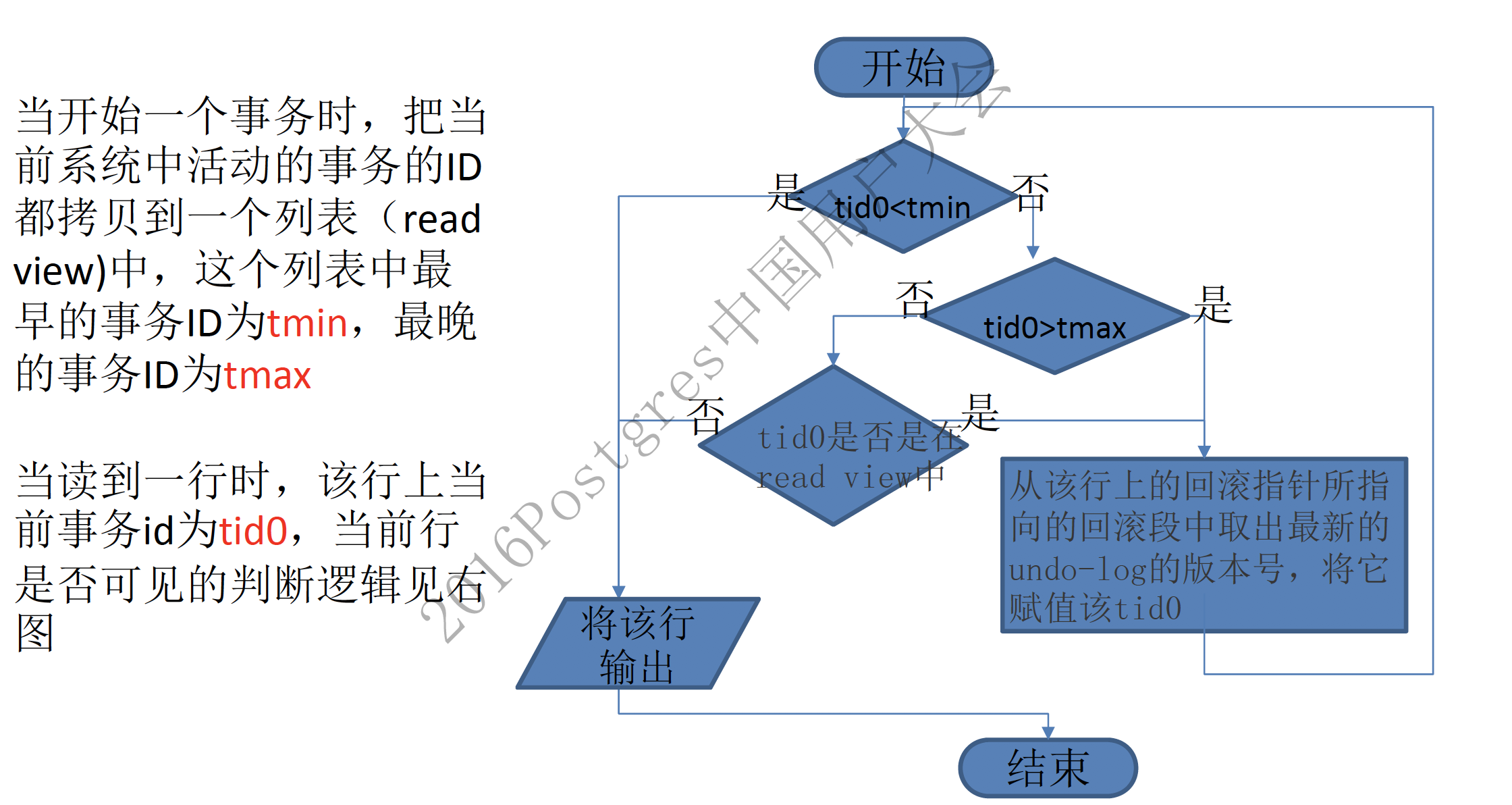 )
)
相关源码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20bool changes_visible(
trx_id_t id,
const table_name_t& name) const
MY_ATTRIBUTE((warn_unused_result))
{
ut_ad(id > 0);
//如果ID小于Read View中最小的, 则这条记录是可以看到。说明这条记录是在select这个事务开始之前就结束的
if (id < m_up_limit_id || id == m_creator_trx_id) {
return(true);
}
check_trx_id_sanity(id, name);
//如果比Read View中最大的还要大,则说明这条记录是在事务开始之后进行修改的,所以此条记录不应查看到
if (id >= m_low_limit_id) {
return(false);
} else if (m_ids.empty()) {
return(true);
}
const ids_t::value_type* p = m_ids.data();
return(!std::binary_search(p, p + m_ids.size(), id)); //判断是否在Read View中, 如果在说明在创建Read View时 此条记录还处于活跃状态则不应该查询到,否则说明创建Read View是此条记录已经是不活跃状态则可以查询到
}
这里需要注意的是,InnoDB的MVCC仅针对RR和RC这两种隔离级别而言。对于Read Uncommitted,由于读取到的总是最新的数据,不管该记录是否已经提交,因此不会遍历版本链,也就不需要MVCC;对于Serializable级别,从MVCC并发控制退化为基于锁的并发控制,读加共享锁,写加排他锁,读写相互阻塞。而对于RR和RC级别,它们对于MVCC的可见性实现也是不同的:
- RC:事务内的每个查询语句都会重新创建read view,这样就会产生不可重复读的现象发生
- RR:事务开始时创建read view,直到事务结束的这段时间内每一次查询都不会重建read view,从而实现了可重复读
总结
MVCC是一种用来解决读-写冲突的无锁并发控制机制,它所支持的RR和RC两种隔离级别,读写之间不会被阻塞,大大提高了并发性能。InnoDB实现的四种隔离级别,总体就是通过MVCC+2PL实现的。