前言
这段时间通读了一遍Raft论文,虽说其相较Paxos算法而言浅显易懂了许多,但是倘若真正深入理解其中的一些细节,依然还是有许多比较复杂的地方。因此,本文将着重记录自己对于论文中的一些难点的思考过程,而对于Raft的一些基础概念将不会再花篇幅介绍。本文结论大多比较主观,如有疑问欢迎指出。
强一致or最终一致性
在第一次读完Raft论文后,产生的第一个思考就是Raft到底是属于强一致性还是最终一致性。因为Raft并不需要将日志复制到每个节点上才返回,而只要大多数节点都收到即可,因此容易误以为Raft属于一个最终一致性的协议。但实际上,根据强/弱/最终一致性的简单定义:
强一致性集群中,对任何一个节点发起请求都会得到相同的回复,但将产生相对高的延迟。而弱一致性具有更低的响应延迟,但可能会回复过期的数据,最终一致性即是经过一段时间后终会到达一致的弱一致性。
Raft是属于强一致性的,客户端不会读到过期的结果,且并不要求将每个写请求复制到集群中的每个节点上。这是由于Raft的领导人完全特性保证了领导人一定拥有所有已经被提交的日志条目,并且在论文中还提到:
Raft handles this by having the leader exchange heartbeat messages with a majority of the cluster before responding to read-only requests.
即一个Leader在响应只读请求之前,需要先和集群中的大多数节点交换一次心跳,来及时发现自己是否已经被废黜了。
提交之前任期内的日志条目
刚开始看到论文中5.4.2节时不太清楚作者究竟想表达什么,后来反复阅读了原文才知晓其中的含义。
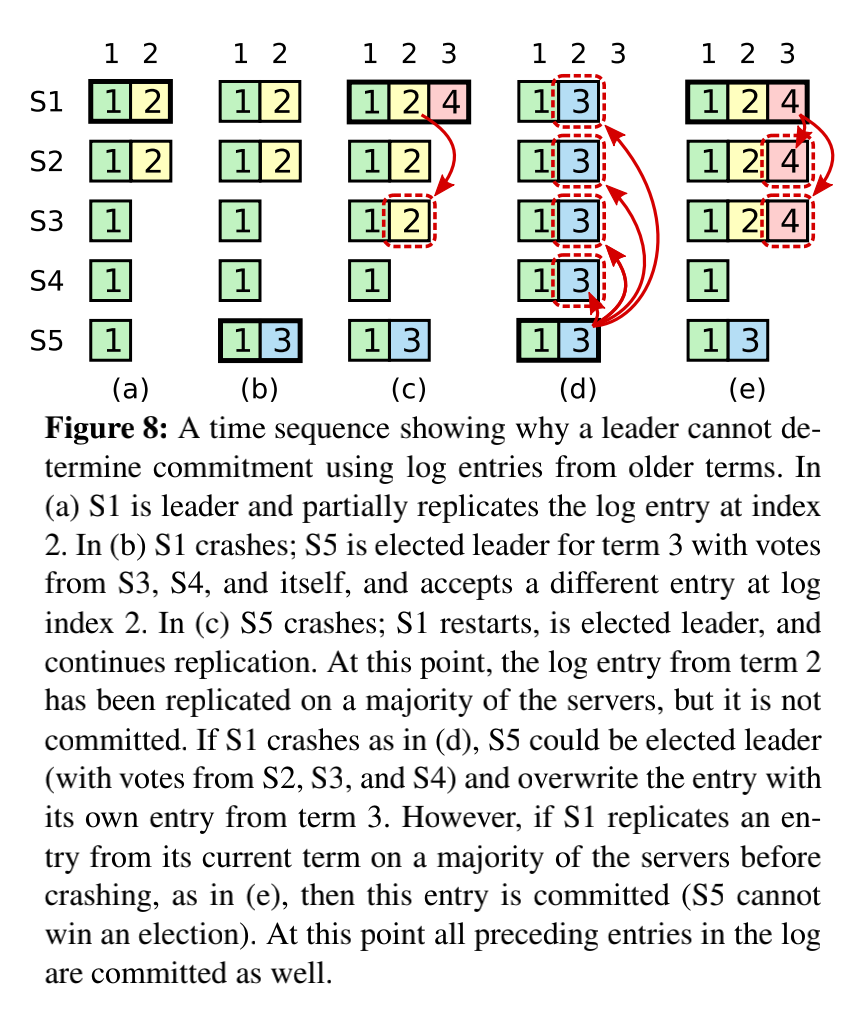
这一段表达的意思其实就是Leader只会提交自己任期内副本超过半数的日志条目,就算看到了(甚至是复制了)之前任期的日志条目副本超过半数了,依然也不会主动去提交,因为它是有可能被覆盖的(如图8中d的情况),一旦提交并返回客户端成功就出错了(也就是非线性一致性,即之前响应客户端commit成功的请求被回退了)。所以把提交的时机交给当前任期的日志被成功复制后,提交当前任期的日志时会间接提交之前任期的日志(因为提交就是移动一下commitIndex),这样才能保障提供线性一致性。
在某篇博客中对此有个更通俗易懂的解释:
提交的限制 5.4.2 这个图配上说明非常迷惑,其实他就是说如果leader的current term是4,你不能直接去提交自己的最大日志是term=2的那条日志,就算这个日志leader知道已经被所有机器接受也不能提交这个日志。如果你提交该日志就可能被s5覆盖,破坏raft的安全,当然不提交也会被s5覆盖,但raft只保证被提交日志的安全性;比current term小的日志term,Leader就不会去统计该日志是否被大多数节点接受。只有当有个新日志并且其必须term=4被大多数节点接受,然后可以直接提交这个term=4的新日志;这样可以导致之前的term=2的日志也被默认提交了。
除此之外,为了防止当前任期的写请求迟迟不来,导致Leader没法提供对这部分不知道有没有提交的日志的读服务,所以Raft通过Leader在任期开始的时候提交一个空白的没有任何操作的日志条目(NO-OP LogEntry)到日志中去,以此保障快速进入正常可读状态。
First, a leader must have the latest information on
which entries are committed. The Leader Completeness
Property guarantees that a leader has all committed entries, but at the start of its term, it may not know which
those are. To find out, it needs to commit an entry from
its term. Raft handles this by having each leader commit a blank no-op entry into the log at the start of its
term.
集群成员变更
集群成员变更是整篇论文里最晦涩难懂的,其核心问题就是在于各个节点见到新配置的时间点是不同的,从而导致两个节点各自使用新老配置完成选举,从而产生两个Leader: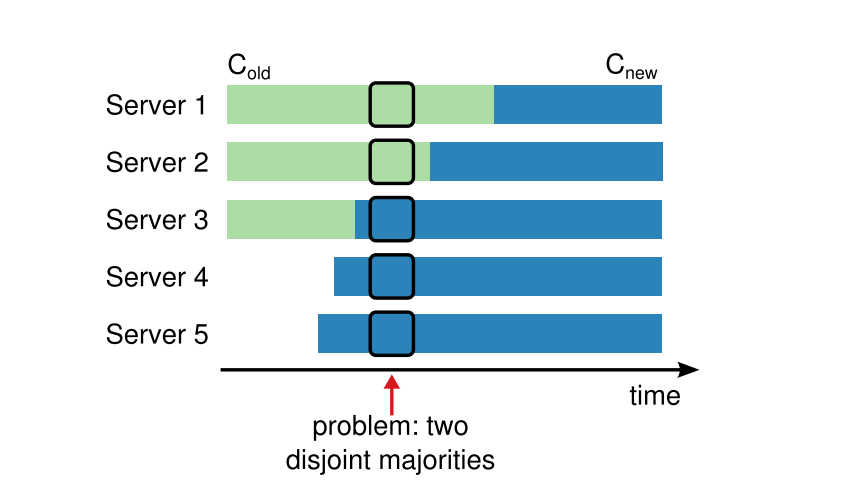
在上图的箭头指向的时间点,Server1可以通过Server1和Server2的投票完成选举,而Server5可以通过Server3、Server4、Server5的投票完成选举。因此,Raft使用joint consensus的方式避免多个节点同时单方面使用新老配置作出决策。
joint consensus主要分两阶段修改配置,并且在更新过程中,完全不影响集群的可用性:
- 当Leader收到新配置C_new的时候,他首先是把它与老配置做并集,生成一个C_old_new配置。Leader会将C_old_new日志发到所有成员,直到大多数已经成功收到这个配置的日志。
- 如果大多数机器都收到C_old_new日志,Leader便将C_old_new提交,然后Leader再把C_new发到集群中。
这里有几点需要额外注意:
- 一旦一个服务器将新的配置日志条目增加到它的日志中,他就会用这个配置来做出未来所有的决定,而无论是否已经提交。
- C_old_new达成一致需要分别在两种配置上获得大多数的支持。
- 一定要等到C_old_new被提交后再创建一条关于C_new配置的日志条目并复制给集群才是安全的。因为如果没有提交,就算被复制给了大多数,也依然有可能被覆盖掉(论文中介绍领导人完整性时有提到这种情况),这时候就又回到了C_old和C_new共同决定的局面。
论文在这部分还指出了三个问题(由于篇幅过长,就不粘贴了)。第一个问题意思是在新机器加入集群时,在配置变更流程开始前,需要先完成数据同步;第二个问题相对来说比较复杂,意思是当C_old_new日志提交后,根据领导人完整性特性,仅具有C_old日志的机器已经无法当选Leader,这时候具有C_old_new或C_new日志的机器才可以当选Leader(这取决于赢得选举的候选人是否已经接收到了C-new日志),也就是说这时候依然可能依赖C_old的配置。而当C_new提交后,就只有具有C_new日志的机器可以当选Leader,此时就不再需要C_old配置上的机器了,不在C_new配置上的Leader这时候也可以过渡了。
当然,如果最开始的C_old_new日志都提交失败了,被选出来的新领导人可能是使用C-old配置也可能是C-old,new配置,和上面的思路是一样的。
If the leader crashes,
a new leader may be chosen under either Cold or Cold,new,
depending on whether the winning candidate has received
Cold,new.
实际上,现在开源的Raft实现上基本都不采用这种模式,而是更为简单的Single Cluster MemberShip Change(单节点变更算法)。我们可以注意到上面之所以会产生两个Leader的本质原因其实在于新旧配置的大多数(Majority)不存在交集,因此,倘若可以让新旧配置的大多数产生交集,这个交集就可以充当仲裁者的角色,单节点变更算法就是基于这个思想,每次只允许出现一个节点变更(增加或减小),那么新配置和旧配置的大多数总会相交。
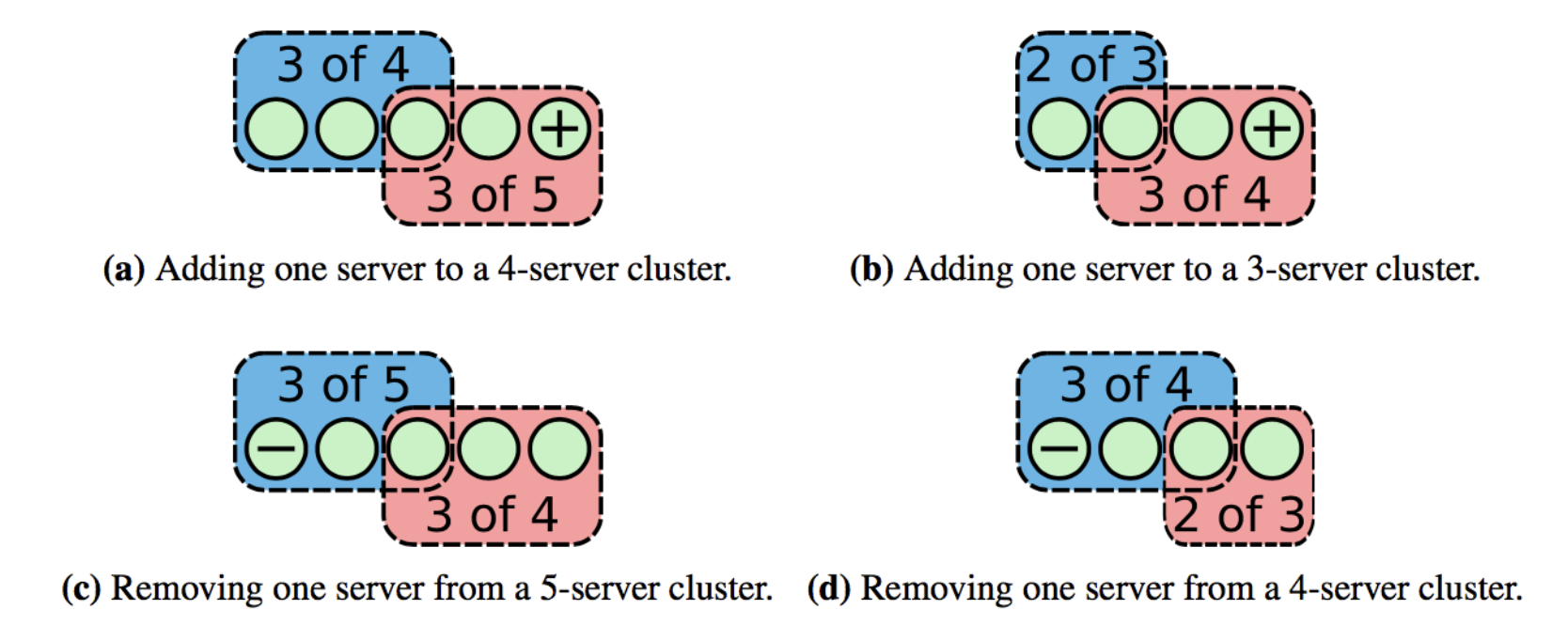
而关于这个算法依然还有许多注意点,比如说如下这种情况:
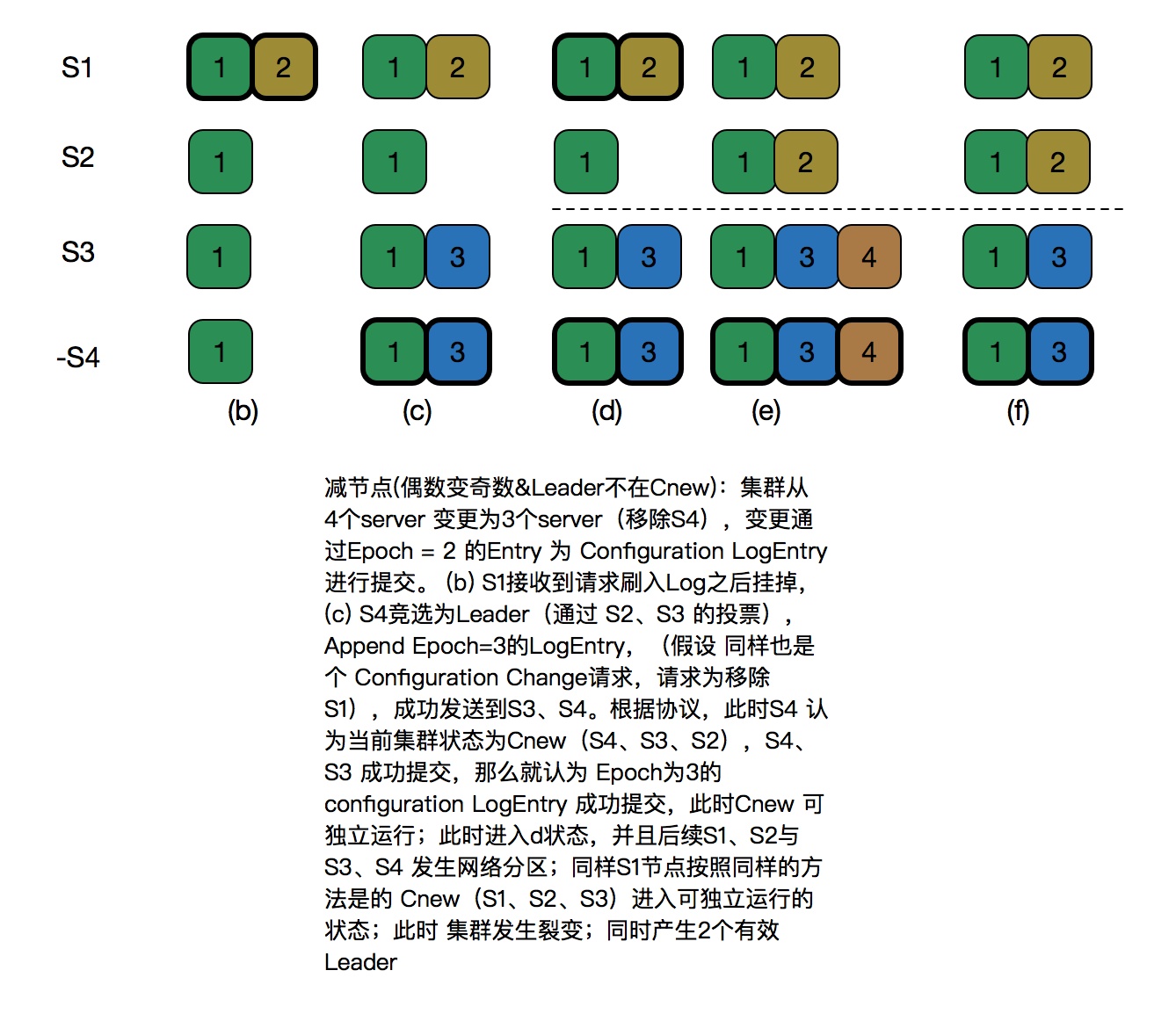
对于这个问题,braft提出“Leader启动的时候就发送NO_OP请求,将上一个AddPeer/RemovePeer变为committed, 并使未复制到当前Leader的AddPeer/RemovePeer失败。直等到NO_OP请求committed之后, 可以安全地创建一个新的configuration并开始复制它。”
Leader启动的时候先发送一个AddPeer或者是NOP请求是非常重要的:如果集群数量为偶数,并且上一个Leader最后在进行节点变更的时候宕机没有commit到多数;新的Leader如果启动就改变其节点集合,按照新节点集可能判断为Committed,但是之前老的Leader启动之后按照新的节点集合形成另外一个多数集合将之前未Commit的节点变更日志变为Committed,这样就产生了脑裂,可能会造成数据丢失。新的Leader启动之后必须Commit一条数据非节点变更日志后才能够进行发起节点变更,这条Committed的非节点变更日志可以保证至少跟之前UnCommitted的日志有一个节点交集,这样就可以保证UnCommitted的节点变更日志不会再变为Committed。详细讨论参见:https://groups.google.com/forum/#!topic/RAFT-dev/t4xj6dJTP6E