前言
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
跳跃表支持平均O(logN)和最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。在大部分情况下,跳跃表的效率可以和平衡树相媲美,并且因为跳跃表的实现比平衡树要来得更为简单,所以有不少程序都使用跳跃表来代替平衡树。
跳跃表的实现
Redis的跳跃表由zskiplistNode和zskiplist两个结构定义,其中zskiplistNode结构用于表示跳跃表节点,而zskiplist结构则用于保存跳跃表节点的相关信息,比如节点的数量,以及指向表头节点和表尾节点的指针等等。
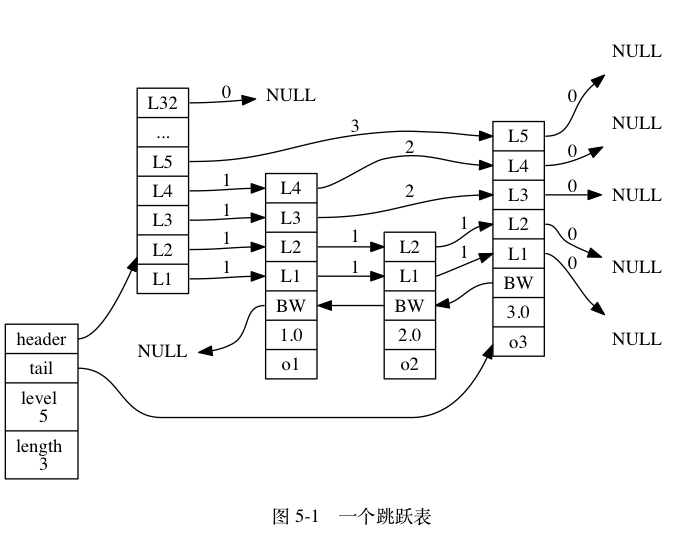
图5-1展示了一个跳跃表示例,位于图片最左边的是zskiplist结构,该结构包含以下属性:
header:指向跳跃表的表头节点。tail:指向跳跃表的表尾节点。level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。
位于zskiplist结构右方的是四个zskiplistNode结构,该结构包含以下属性:
- 层(level):节点中用 L1 、 L2 、 L3 等字样标记节点的各个层,L1 代表第一层, L2 代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离。每次创建一个新跳跃表节点的时候, 程序都根据幂次定律(power law,越大的数出现的概率越小)随机生成一个介于1和32之间的值作为层的高度。跨度是用来计算排位(rank)的,在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来,得到的结果就是目标节点在跳跃表中的排位。
- 后退(backward)指针:节点中用 BW 字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。跟可以一次跳过多个节点的前进指针不同,因为每个节点只有一个后退指针,所以每次只能后退至前一个节点。
- 分值(score):各个节点中的 1.0 、 2.0 和 3.0 是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。
- 成员对象(obj):各个节点中的 o1、o2 和 o3 是节点所保存的成员对象。分值相同的节点将按照成员对象在字典序中的大小来进行排序,成员对象较小的节点会排在前面,而成员对象较大的节点则会排在后面。
注意表头节点和其他节点的构造是一样的:表头节点也有后退指针、分值和成员对象,不过表头节点的这些属性都不会被用到,所以图中省略了这些部分,只显示了表头节点的各个层。
虽然仅靠多个跳跃表节点就可以组成一个跳跃表,但通过使用一个zskiplist结构来持有这些节点,程序可以更方便地对整个跳跃表进行处理,比如快速访问跳跃表的表头节点和表尾节点,又或者快速地获取跳跃表节点的数量(也即是跳跃表的长度)等信息。
查找
跳跃表的查找是从最上层的跳跃区间大的层开始的,从头结点开始和前进指针指向的节点进行比较,如果大于前进节点,则继续向前找,如果小于前进节点,则到下一层继续查找,直到找到为止。
插入
跳跃表的插入操作和链表的插入操作十分相似,大致过程如下:
- 查找到需要插入的位置
- 申请新的结点
- 调整指针
因为找到插入点之后,新生成节点,新节点的层的高度是随机生成的,故需要保存所有层的后继指针。
删除
删除和插入类似,大致过程如下:
- 查找到需要删除的结点
- 删除结点
- 调整指针
时间复杂度
- 最坏时间复杂度 О(n)
- 平均时间复杂度 O(logn)
Redis中的应用
Redis使用跳跃表作为有序集合键的底层实现之一:如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时,Redis就会使用跳跃表来作为有序集合键的底层实现。而之所以不使用红黑树,是因为在性能相差不大的情况下,跳跃表实现更为简单。
总结
- 跳跃表是有序集合的底层实现之一。
- Redis的跳跃表实现由
zskiplist和zskiplistNode两个结构组成,其中zskiplist用于保存跳跃表信息(比如表头节点、表尾节点、长度),而zskiplistNode则用于表示跳跃表节点。 - 每个跳跃表节点的层高都是1至32之间的随机数。
- 在同一个跳跃表中,多个节点可以包含相同的分值,但每个节点的成员对象必须是唯一的。
- 跳跃表中的节点按照分值大小进行排序,当分值相同时,节点按照成员对象的大小进行排序。