简介
Google File System(简称GFS)是一个面向大规模数据密集型应用的、可伸缩的分布式文件系统,其运行在廉价的普通硬件设备上,并且是基于Linux文件系统之上的。GFS主要是针对以下场景而设计的:
- 组件经常失效。
- 存储大文件(数GB的文件非常普遍)。
- 写操作主要是顺序的追加写,而不是覆盖写。
架构
GFS系统包含三部分:客户端、单独的Master节点、多台Chunk服务器。所有这些机器通常都是普通的Linux机器,运行着用户级别的服务进程。
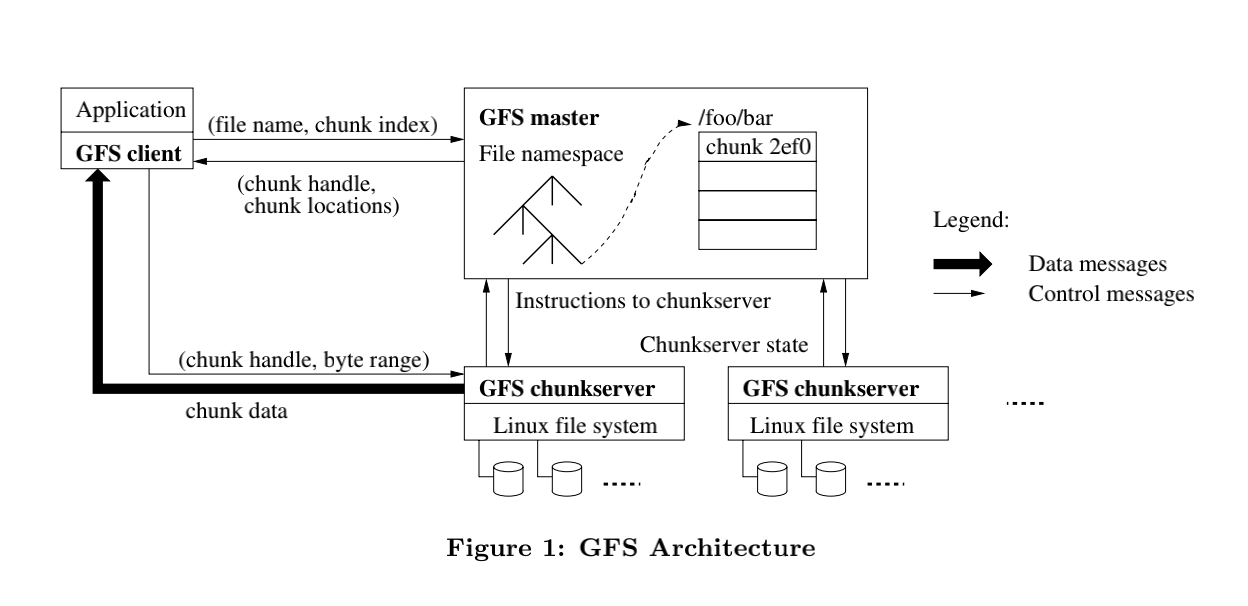
Chunk
GFS存储的文件被划分为固定大小的Chunk。每个Chunk在创建时会被分配一个Chunk句柄,即一个不变的、全局唯一的64位的ID。Chunk服务器把Chunk以Linux文件的形式保存在本地硬盘上,按照Chunk句柄和字节范围来读写Chunk数据。为了可靠性,每个Chunk被复制到多个Chunk服务器上,默认是3份(由复制因子指定)。
Chunk的大小为64M。选择这么大的Chunk尺寸有以下几个优点:
- 减少了客户端和Master节点通讯的需求。
- 客户端能够对一个块进行多次操作,从而与Chunk服务器保持较长时间的TCP连接来减少网络负载。
- 减少了Master节点需要保存的元数据的数量。
但大的Chunk尺寸也是有其缺陷的,即小文件包含较少的Chunk甚至只有一个Chunk,当有许多的客户端对同一个小文件进行多次访问时,存储这些Chunk的Chunk服务器就会变成热点。这个问题可以通过增大复制因子来解决。
这里还有一个值得思考的地方,即GFS对数据的冗余是以Chunk为基本单位而不是机器(或者说文件)。以机器为单位进行冗余的优点是简单方便,但是伸缩性不好,不能充分利用资源;而以Chunk为基本单位,虽然Master节点上需要存更多的元数据,但一个Chunk的信息也就64字节左右,而Chunk本身的粒度又有64M这么大,加之在Master中Chunk的位置信息是不持久化的,所以这并不会给Master带来太多的负担。
Master
Master主要存储三种类型的元数据:文件和Chunk的命名空间(GFS按层级目录管理文件)、文件到Chunk的映射关系
、Chunk的位置。所有的元数据均被保存在Master的内存中,前两种也会持久化保存,即通过记录操作日志,存储在Master的本地磁盘并且复制到远程机器。使用操作日志允许我们更简单可靠的更新Master状态,不会因为Master的宕机导致数据不一致。但是,Master不会持久化存储Chunk的位置,相反,Master会在启动时询问每个Chunk服务器以获取它们各自的Chunk信息,新Chunk服务器加入集群时也是如此。
操作日志对于GFS至关重要,它是元数据唯一的持久化存储记录。只有在把日志复制到多台远程机器,并且只有把相应的日志记录写入到本地以及远程机器的硬盘后才能响应客户端。Master节点在灾难恢复时通过重演操作日志把文件系统恢复到最近的状态,为了缩短Master启动的时间,我们必须使日志足够小,所以Master服务器在日志增长到一定量时对系统状态执行快照,而不需要从零开始回放日志,仅需要从本地磁盘装载最近的快照,并回放快照之后发生的有限数量的日志。
当然,在Master节点上持久化Chunk位置信息也不是不行,但由于只有Chunk服务器才能最终确定一个Chunk是否在它的硬盘上,所以定期轮询的方式更为简便和可靠,否则需要考虑Chunk服务器和Master服务器的数据同步问题,其实没这个必要在Master节点上大费周章的维护一个一致性视图。
Master也负责管理一些影响整个系统的活动,比如Chunk租赁管理、孤儿Chunk的垃圾回收,以及Chunk服务器之间的Chunk迁移。Master与Chunk服务器保持常规的心跳,以确定Chunk服务器的状态。
Client
GFS客户端代码以库的形式被链接到客户程序里。客户端只在获取元数据时与Master交互(客户端会缓存元数据),真实的数据操作会直接发至Chunk服务器。客户端和Chunk服务器都不会缓存文件数据。
读取流程
- 应用程序调用GFS客户端提供的接口,指明文件名和字节偏移。
- GFS客户端根据固定的Chunk大小将字节偏移转换成Chunk索引,然后将文件名和Chunk索引发送给Master节点。
- Master节点将相应的Chunk ID和Chunk的位置信息响应给客户端(客户端此时用文件名和Chunk索引作为key缓存这些信息)。
- GFS客户端向最近的持有副本的Chunk服务器发出读请求,请求中包含Chunk id与字节范围。
在对这个Chunk的后续读取操作中,客户端不必再和Master节点通讯了,除非缓存的元数据信息过期或者文件被重新打开。
写入流程
GFS引入了租约(lease)机制。Master节点为Chunk的其中一个副本建立一个租约,这个副本就是Primary,Primary对Chunk的所有更改操作进行序列化,所有的副本都遵从这个序列进行修改操作。
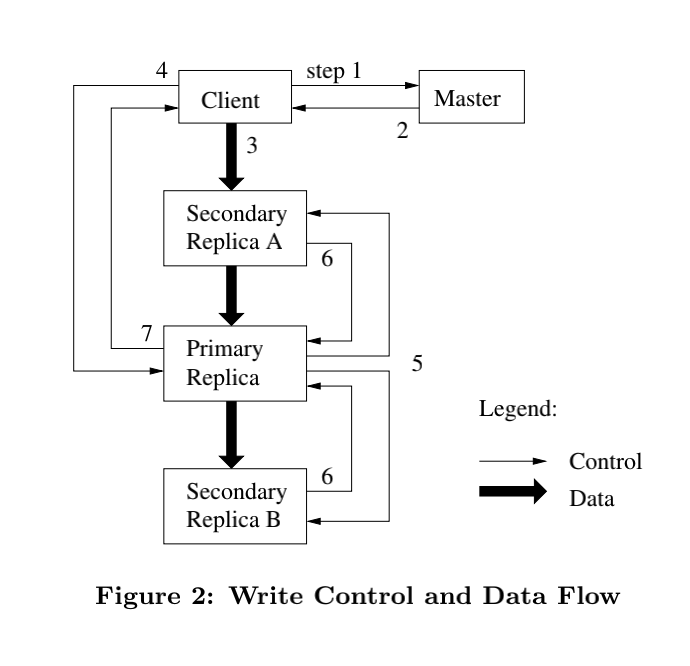
- 客户端向Master节点询问哪个Chunk服务器是Primary以及其它副本(Secondary)的位置,客户端在本地缓存这些信息。
- 客户端将数据链式推送到所有副本上。
- 客户端通知Primary提交。
- Primary提交成功后,通知所有Secondary提交。
- Secondary成功后响应Primary,Primary响应客户端。
论文中说“设计租约机制的目的是为了最小化Master节点的管理负担”,刚开始未能理解其中的原因。实际上,由于租约的存在,客户端就不必每次进行写入时都询问Master由哪个Chunk服务器负责全局顺序,只要在租约的有效期内,客户端就可以一直联系该Chunk服务器,从而减轻了Master的负担。
为了提高网络效率,GFS还将数据流和控制流分开,并且数据在Chunk服务器间链式推送(每台机器都尽量选择最近的),从而充分利用每台机器的带宽,避免网络瓶颈和高延时的连接,最小化推送所有数据的延时。不同于主从模式对Primary的压力,这种链式模式下每台机器所有的出口带宽都用于以最快的速度传输数据。除此之外,GFS还使用TCP流式传输数据,即一旦Chunk服务器收到数据就立刻开始推送,而不用等收到完整的数据再发往下一个副本。
一致性模型
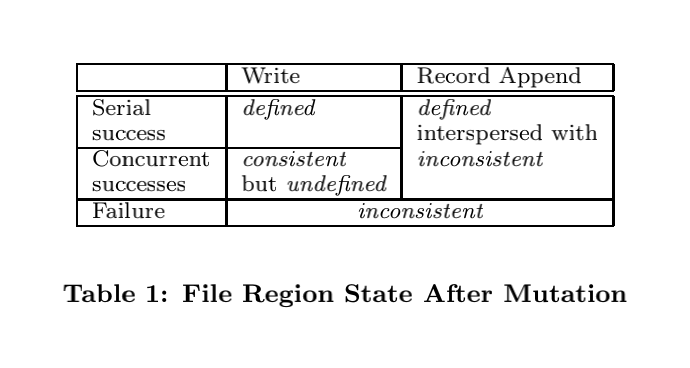
- 一致的:对于文件区域A,如果所有客户端从任何副本上读到的数据都是相同的,那A就是一致的。
- 已定义的:如果A是一致的,并且客户端可以看到写入的完整数据,那A就是defined,即结果是可预期的。已定义一定是一致的。
GFS所谓的宽松的一致性可能有点晦涩。
写操作(修改操作)包含覆盖写和追加写两种模式。覆盖写由用户指定offset,所以在并发写入时,可能各个用户写入的数据相互混合,我们就无从得知这一堆混合的数据里都是哪些操作分别写入了哪部分数据,但是由于操作在所有的副本上都以相同的顺序执行,读的时候确实是相同的结果,所以就是所谓的“一致但是未定义”。而对于追加写来说,offset是由GFS选择的,GFS保证操作“至少会成功一次”,这种重试机制导致了“已定义但部分不一致“的情况。举个例子,假设追加写操作在两个副本上都成功了,而在最后一个副本上失败了(这个时候仅仅是不一致),那么此时会尝试重试,并且那两个副本上的重复数据不会删除,当重试成功后,因为客户端能看到写入的完整数据,所以是“已定义的”,但由于中间夹杂着不一致的数据,所以是“部分不一致”的,但是对于这种部分不一致,可以通过Checksum或唯一标识符来解决。
命名空间管理和锁
GFS的命名空间就是一个全路径和元数据映射关系的查找表,利用前缀压缩高效的存储在内存中。在存储命名空间的树形结构上,每个节点(绝对路径的文件名或绝对路径的目录名)都有一个关联的读写锁。通常情况下,如果一个操作涉及/d1/d2/dn/leaf,那么操作首先要获得目录/d1、/d1/d2、/d1/d2/dn的读锁和/d1/d2/dn/leaf的读写锁。一个操作必须按特定的顺序来申请锁以预防死锁:首先按命名空间树的层级排序,在相同层级再按字典序。
采用这种锁方案的优点是支持对同一目录的并行操作,目录名的读锁足以防止目录被删除、改名以及被快照,而文件名的写锁序列化了文件创建操作,确保不会多次创建同名的文件。
垃圾回收
GFS在删除文件时是惰性的,也就是说不会立刻回收可用的物理空间,而是像其它修改操作一样先以日志的方式记录,然后将文件名改为一个包含删除时间戳的隐藏文件。Master会定期对命名空间进行扫描,把隐藏了超过一定时间的文件删除(这个时间是可设置的),在此期间可以对这个文件进行恢复(重命名即可)。当隐藏文件从命名空间删除时,Master内存中这个文件的相关元数据才会被删除。Chunk服务器在和Master节点交互的心跳信息中,报告它拥有的Chunk子集的信息,Master节点回复Chunk服务器哪些Chunk在Master节点保存的元数据中已经不存在了,Chunk服务器可以任意删除这些Chunk的副本。
垃圾回收相比直接删除有几个优势:
- 删除消息可能丢失,而垃圾回收方式简单可靠。
- 回收操作被合并到Master节点规律性的后台活动中,开销被分摊。
- 防止文件被意外删除。