简介
MapReduce是一个处理和生成超大数据集的编程模型和相关实现。基于MapReduce,用户只需通过Map和Reduce函数描述自己的计算问题,而不用关心计算在哪个机器上进行、相互之间如何通信、机器故障如何处理等复杂的问题。
执行过程
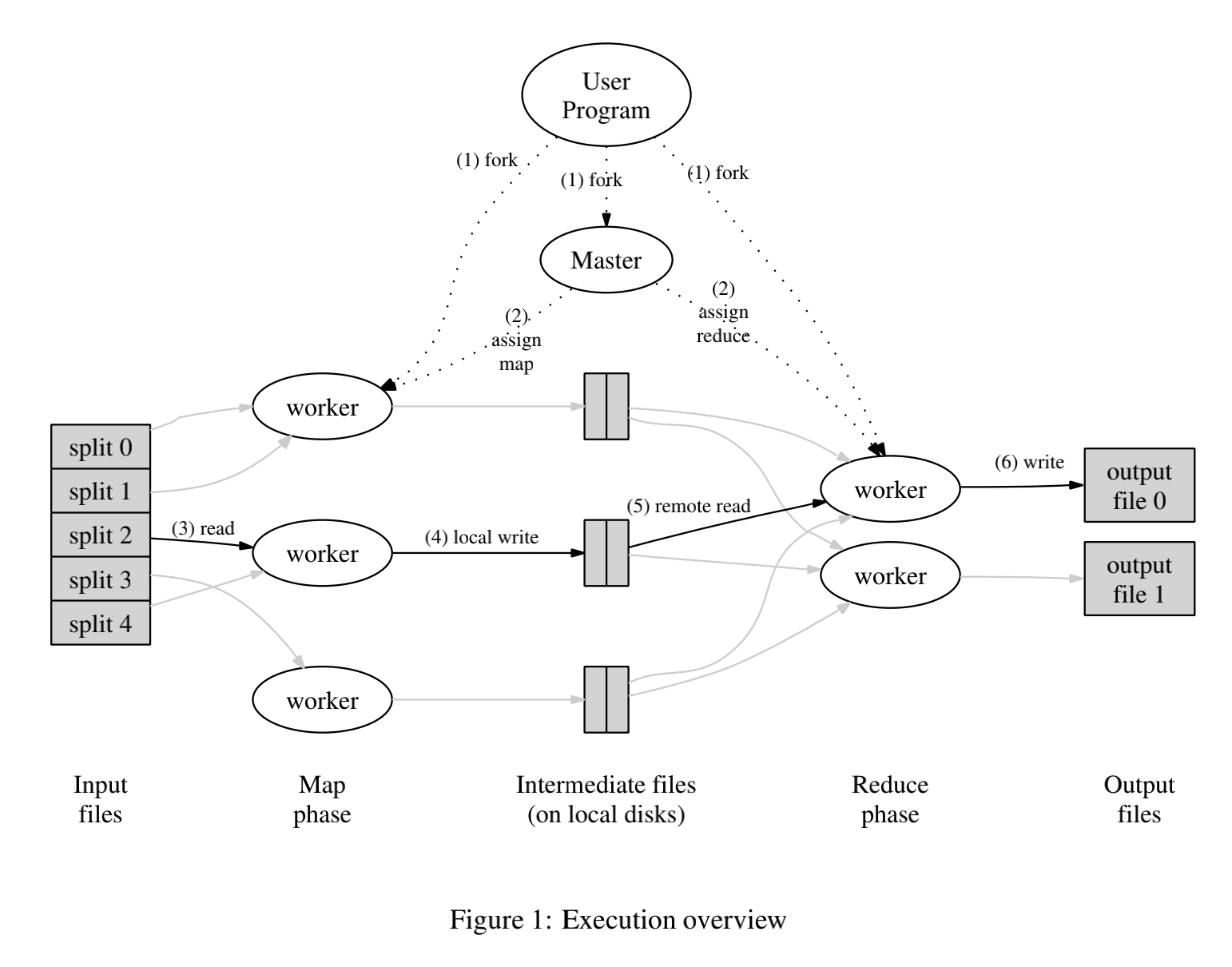
当用户调用MapReduce时,将发生下面的一系列动作:
- MapReduce库首先将输入文件分成M个数据片段,然后用户程序在一组机器集群上创建大量的程序副本。
- 程序副本中有一个Master程序和多个Worker程序,Master程序负责分配任务(M个Map任务和R个Reduce任务)。
- 被分配了Map任务的Worker程序读取相应的输入数据片段,从数据片段中解析出kv对,然后把kv对传给Map函数,Map函数产生中间kv对并缓存在内存中。
- Map Reducer缓存中的kv对通过分区函数分成R个区域并定期写入本地磁盘。这些kv对在本地磁盘上的存储位置将被回传给Master,由Master负责把这些存储位置再传送给Reduce Worker。
- Reduce Worker接受到Master发来的存储位置后,使用RPC从Map Worker所在主机的磁盘上读取这些数据。当Reducer Worker程序读取了所有中间数据后,通过对key进行排序使得具有相同key值的数据聚合在一起。
- Reduce Worker程序遍历排序后的中间数据,对于每一个唯一的中间key值,Reduce Worker程序将这个key值和它相关的中间value值集合传递给用户自定义的Reduce函数。Reduce函数的输出被追加到所属分区的输出文件。
- 当所有的Map和Reduce任务都完成之后,Master唤醒用户程序。此时,用户程序里对MapReduce调用才返回。
成功完成任务后,MapReduce的输出存放在R个输出文件中,而这些文件往往又被作为另外一个MapReduce的输入。
《设计数据密集型应用》书中对该过程的描述图也很形象: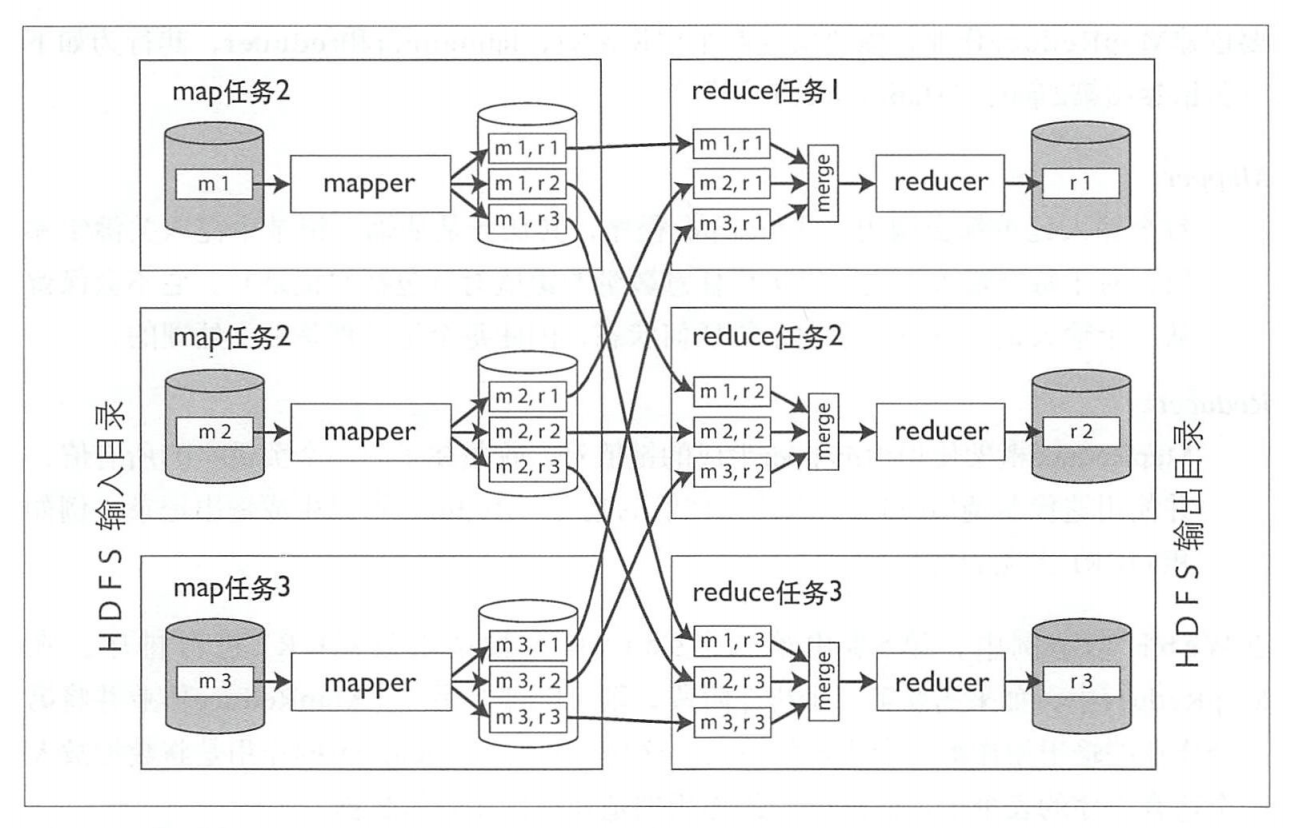
例子
倒排索引的应用: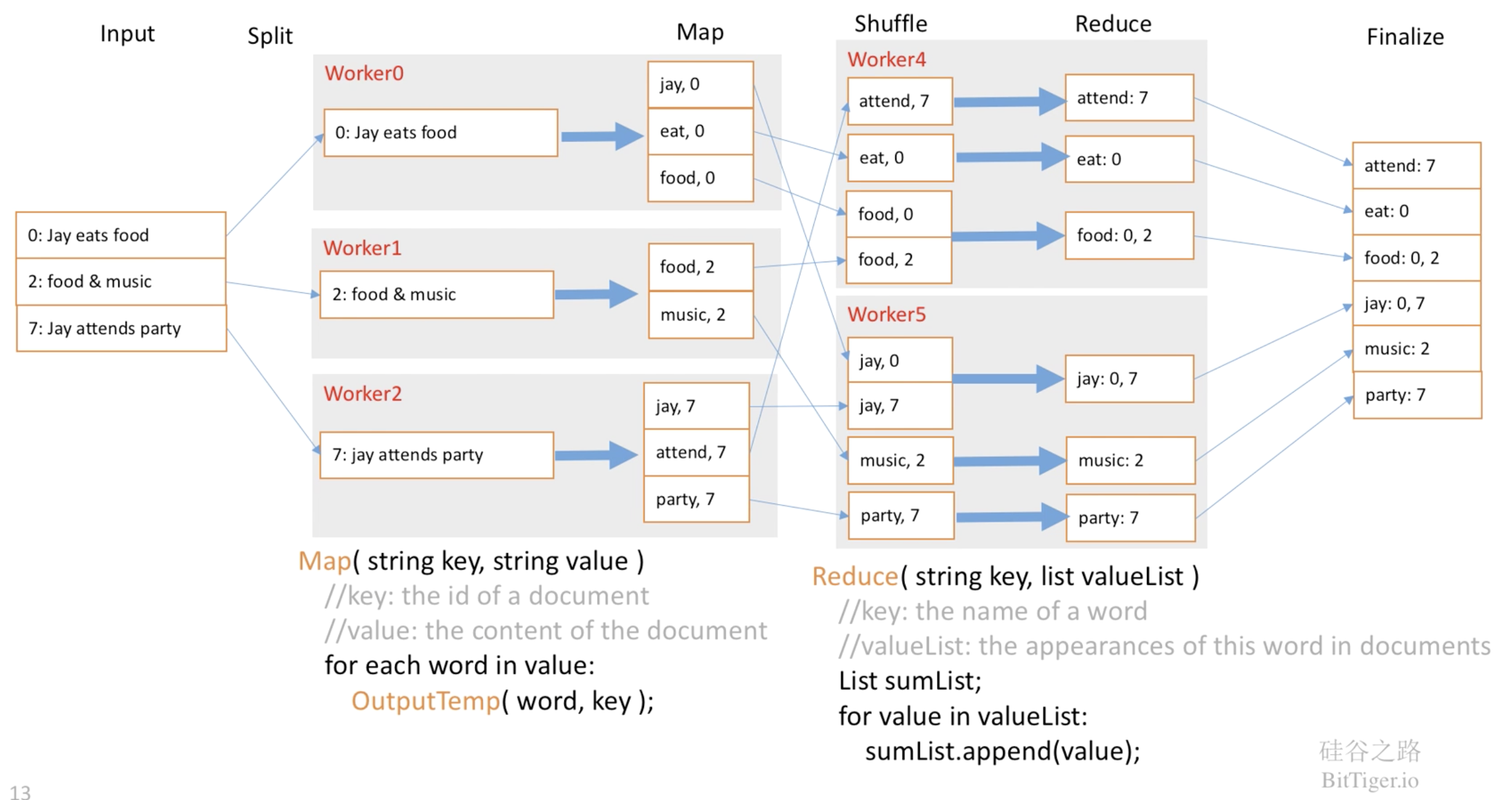
在这个例子中,数据片段个数M和Map Worker数目相同,分区数R也和Reduce Worker数目相同,但在实际应用中,M和R往往比Worker数目要多。
容错
和大多数Unix工具一样,运行MapReduce作业通常不会修改输入,除了生成输出外没有任何副作用。当遇到崩溃和网络问题时,任务可以安全地重试,任何失败任务的输出都被丢弃。因此,容错的设计是十分方便的,MapReduce可以保证作业的最终输出与没有发生错误的情况相同,尽管这其中不得不重试各种任务。
每个工作中的任务把它的输出写到私有的临时文件中,每个Reduce任务生成一个这样的文件,而每个Map任务则生成R个这样的文件:
- 当一个Map任务完成时,Map Worker发送一个包含R个临时文件名的完成消息给Master。如果Master从一个已经完成的Map任务再次接收到一个完成消息,Master将忽略这个消息,否则Master将这R个文件的名字记录在数据结构里。
- 当一个Reduce任务完成时,Reduce Worker以原子的方式把临时文件重命名为最终的输出文件。如果同一个Reduce任务在多台机器上执行,针对同一个最终的输出文件将有多个重命名操作执行,MapReduce依赖底层文件系统提供的重命名操作的原子性来保证最终的文件系统状态仅仅包含一个Reduce任务产生的数据。
本地化调度策略
网络带宽是一个相当匮乏的资源,所以将Worker调度到相应的输入数据所在的机器,从本地机器读取输入数据,从而减少网络带宽的消耗。这也是为什么我们所设的M值最好使得每个独立任务都处理不超过64M的输入数据,因为在GFS中每一个Chunk的大小就是64M,如果输入数据大于64M,就可能得从别的远程机器上读取其它Chunk中的数据,也就加大了网络开销。
备用任务
当一个MapReduce操作接近完成的时候,Master调度备用任务进程来执行剩下的、处理中的任务。无论是最初的执行进程还是备用任务进程完成来任务,我们都把这个任务标记为已完成。并且在上面容错机制已经提到,有两个Worker执行同一个任务是没有任何问题的。
参考资料
- MapReduce: Simplified Data Processing on Large Clusters
- 典型分布式系统分析:MapReduce
- 深入浅出讲解 MapReduce
- Martin Kleppmann. 数据密集型应用系统设计. 中国电力出版社, 2018.