前言
在阅读并总结了《Google File System》和《MapReduce》两篇论文后,终于迎来了谷歌技术“三宝”最后一项Bigtable。令人头疼的是,在通读了整篇论文后,感觉Bigtable相较于前面两篇晦涩难懂太多,尤其是文中提出的各种术语又没有解释的特别清楚,所以很多部分只能靠推测的方式一步步摸索。后来在B站上看到一个讲解视频十分通俗易懂:深入浅出Bigtable,因此本文将结合论文以及视频中的内容进行总结,如果有理解错误的地方,欢迎指出。
简介
Bigtable是一个分布式的结构化数据存储系统,它被设计用来处理海量数据:通常是分布在数千台普通服务器上的PB级的数据。
数据模型
实际上,Bigtable根本不是table,它的物理存储形式其实是一个排序Map。Map的key是行关键字、列关键字以及时间戳的复合结构,而value则是一个简单的string:(row:string,column:string,time:int64)→string。
Bigtable通过行关键字的字典顺序来组织数据,表中的每个行都可以动态分区,每个分区叫做一个Tablet,Tablet是数据分布和负载均衡调整的最小单位。
若干个列可以组成列族,因此列关键字的命名形式是:列族:限定词。用户在使用前必须首先声明有哪些列族,声明后即可在该列族中创建任意列。
每一个数据项都可以包含同一份数据的不同版本,不同版本的数据通过时间戳来索引。并且为了减轻多个版本数据的管理负担,Bigtable可以通过设置参数来对废弃版本的数据自动进行垃圾收集。
架构
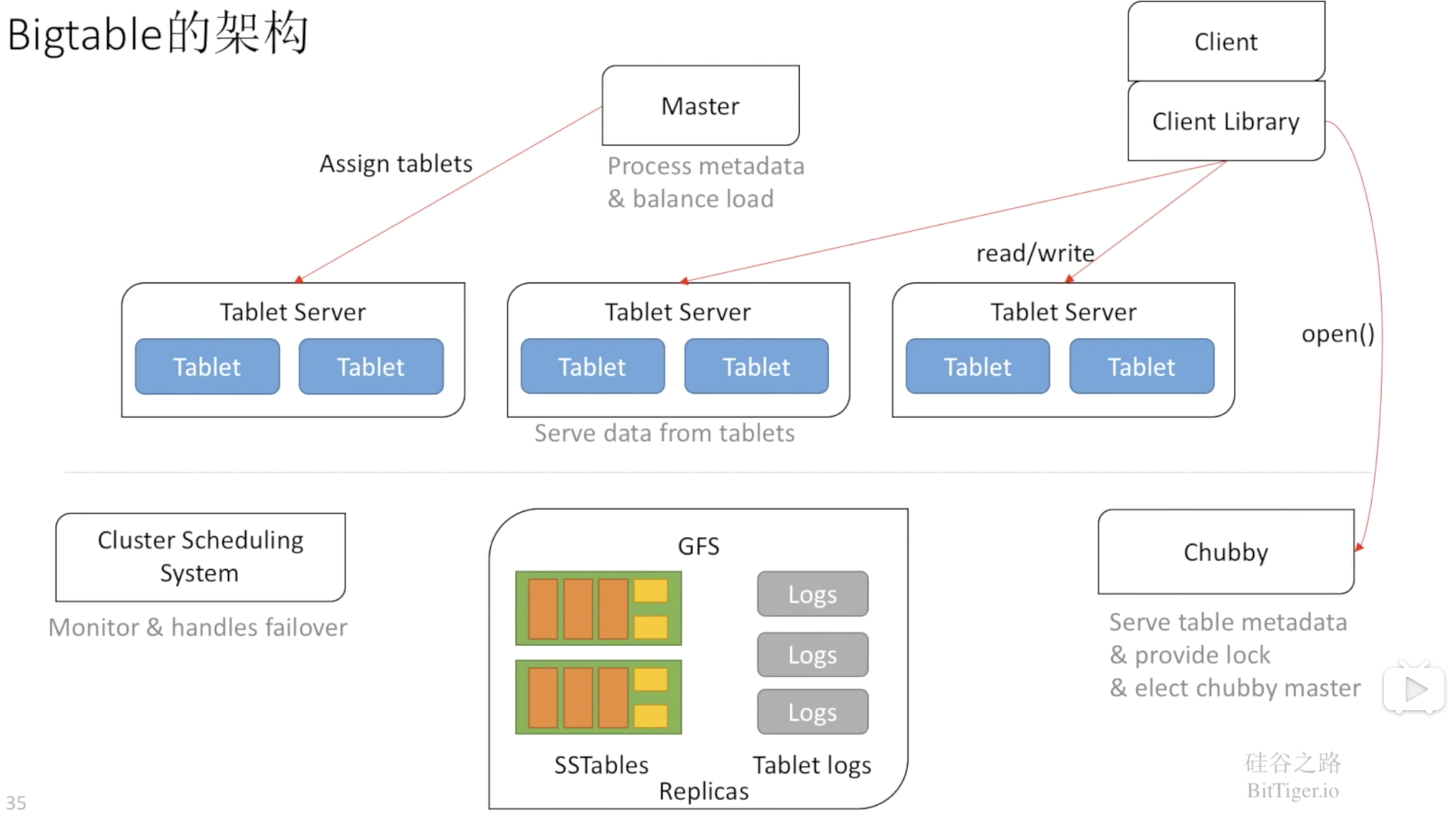
Bigtable包括三个主要的组件:链接到客户程序中的库、一个Master服务器和多个Tablet服务器。Master服务器主要负责以下工作:为Tablet服务器分配Tablets、检测新加入的或者过期失效的Tablet服务器、对Tablet服务器进行负载均衡、对保存在GFS上的文件进行垃圾收集、处理对模式的相关修改操作如建立表和列族。
初始状态下,一个表只有一个Tablet,随着表中数据的增长,它被自动分割成多个Tablet,缺省情况下,每个Tablet的尺寸大约是100MB到200MB。
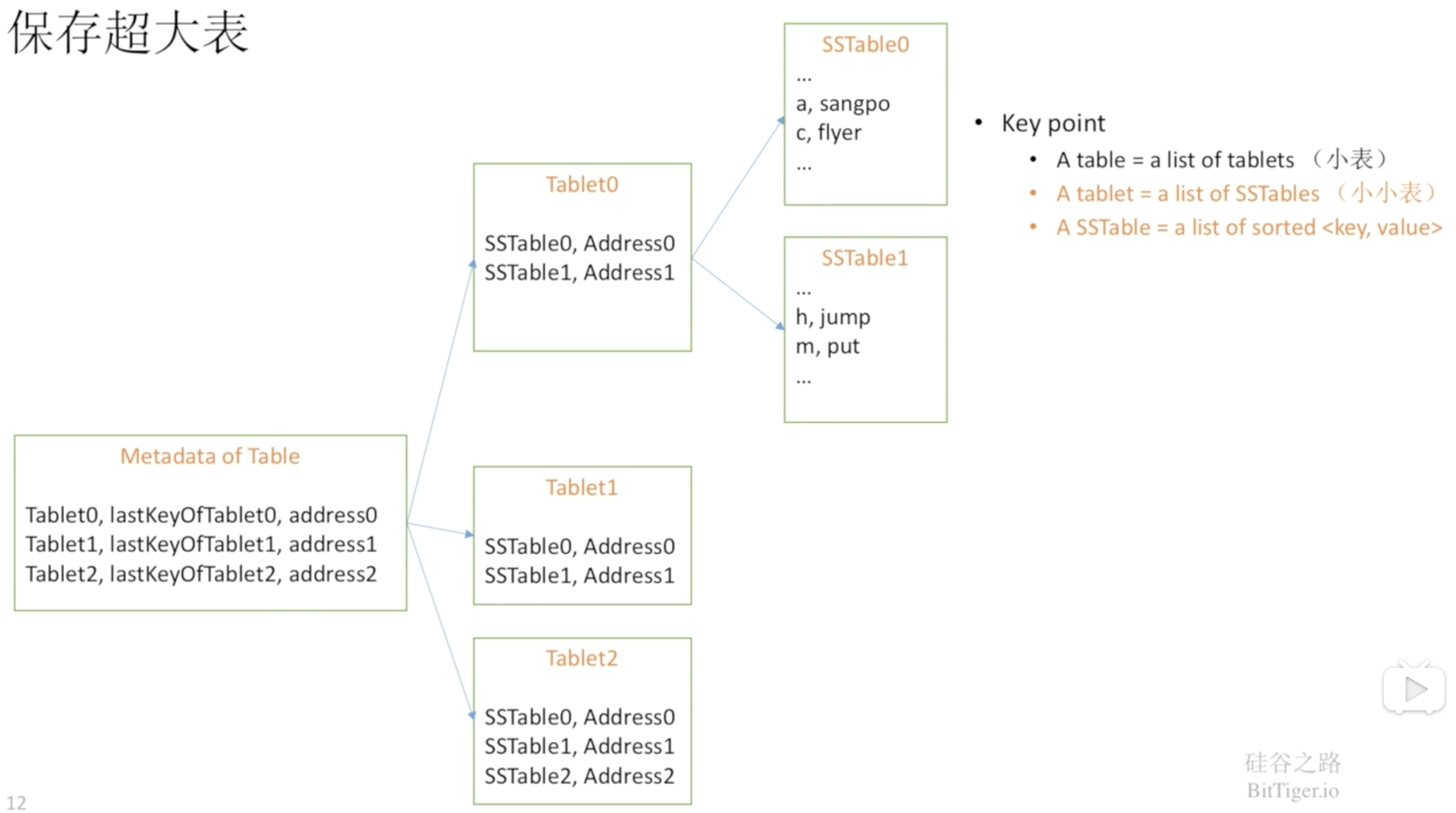
Bigtable使用GFS存储数据文件,并且是SSTable格式的。SSTable是一个持久化的、排序的、不可更改的Map结构(也就是一系列key-value对):
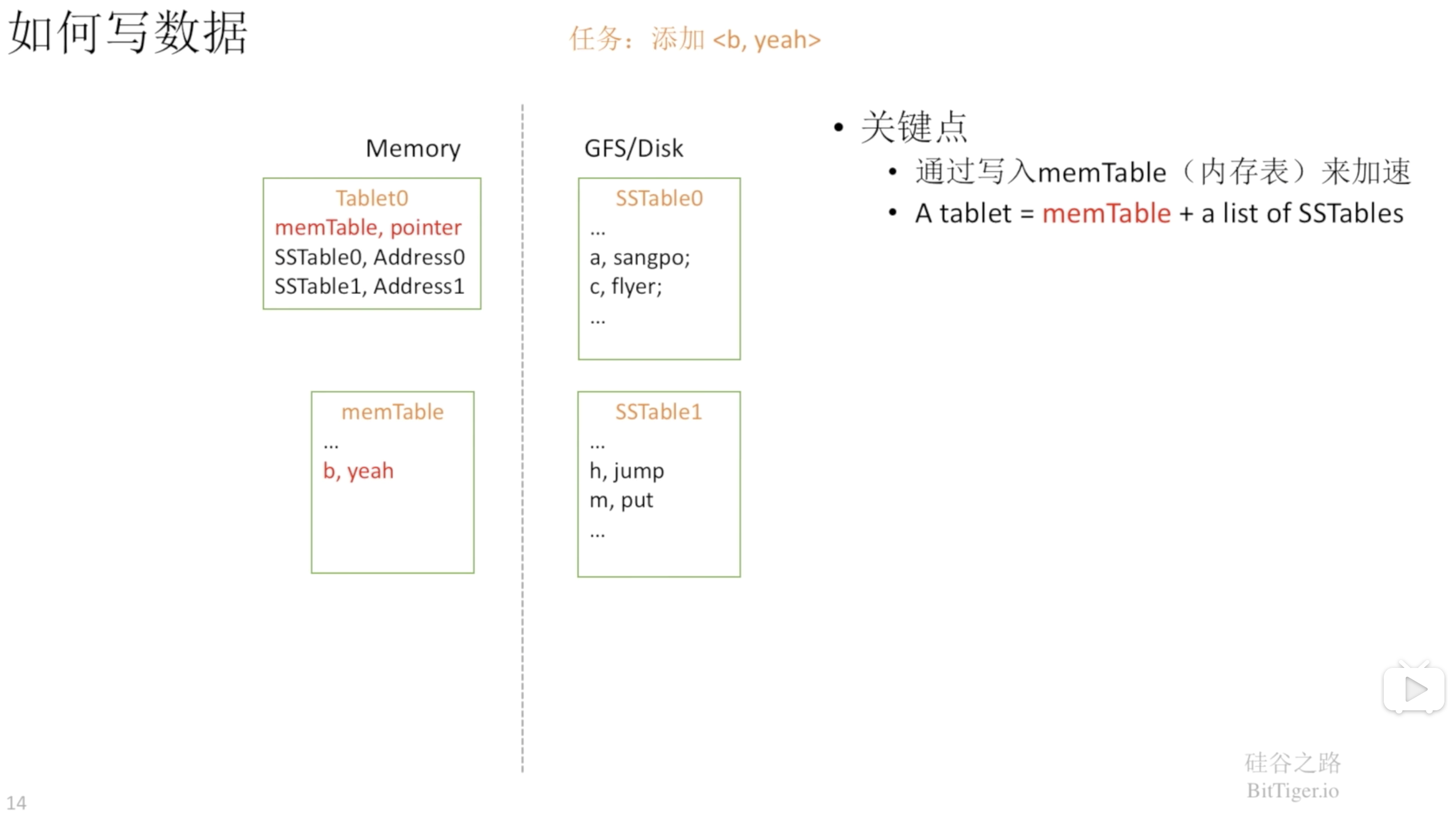
当我们写数据的时候,首先是写在内存表中,而不是直接写入到SSTable中。写入到内存中速度更快,并且排序效率也更高:
当内存表大小达到阈值时,就将数据写入到磁盘,也就是生成一份新的SSTable: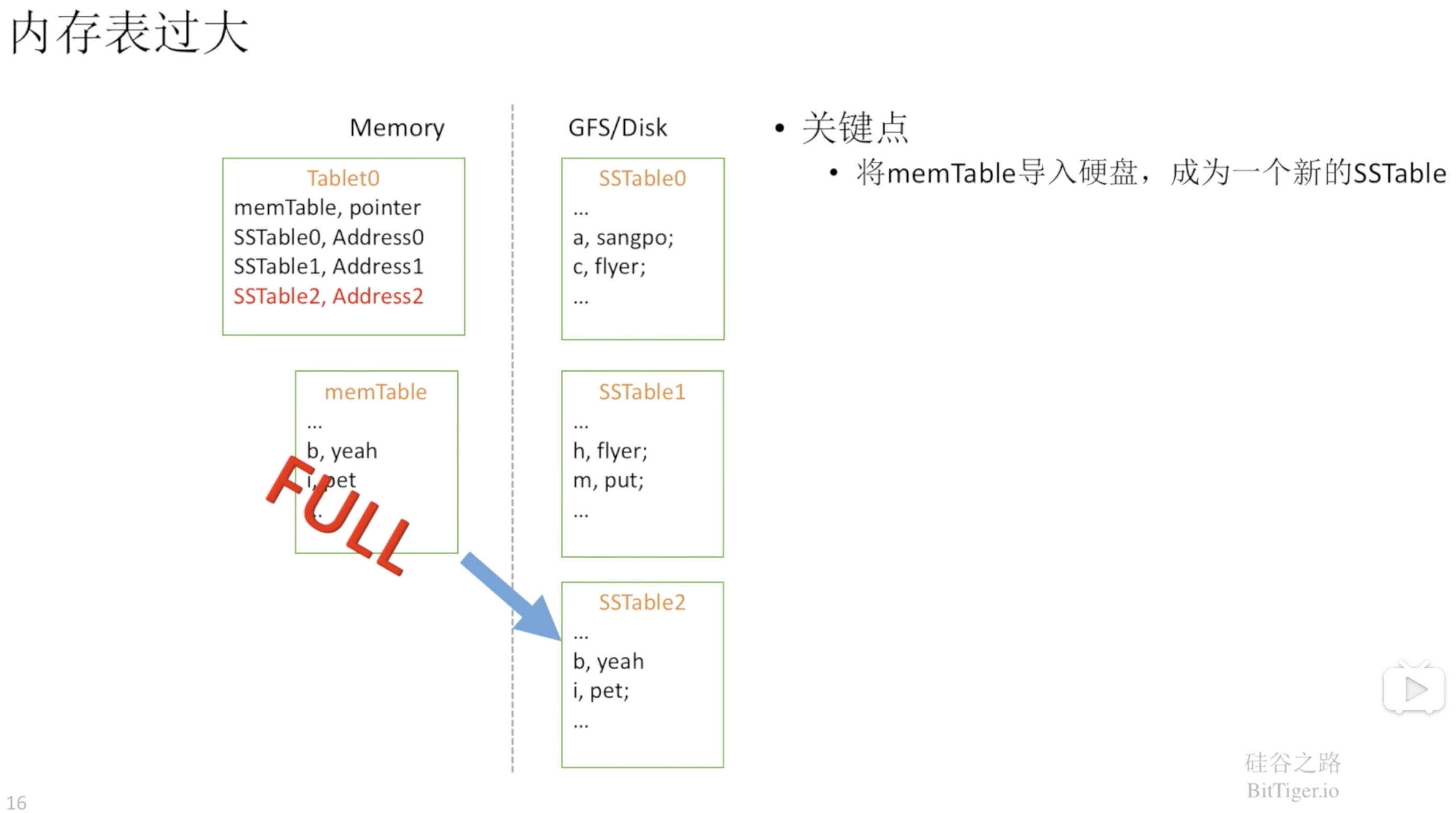
但是在内存中的数据还没写入磁盘的过程中,有可能会发生丢失的情况,所以Bigtable通过预写日志解决了这个问题: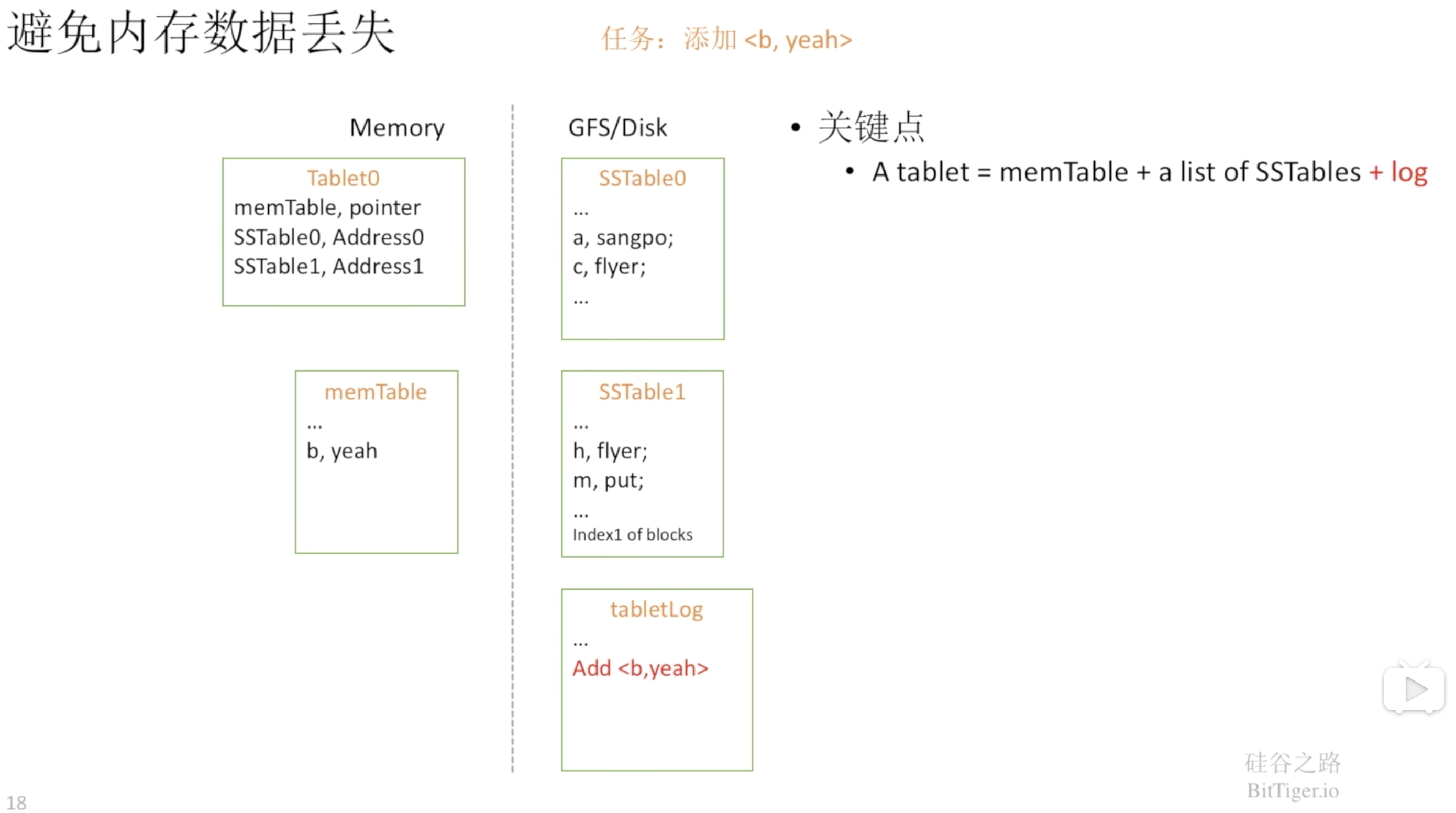
由于上面介绍的写策略,导致了虽然SSTable内部的数据是有序的,但是SSTable之间的数据是无序的,因此,当一个读操作请求到来时,系统首先检查memTable,如果没有找到这个key,就会逆序的一个一个检查SSTable文件,直到key被找到。由此可见,读操作会随着SSTable的个数增加变的越来越慢,因为每一个SSTable都要被检查。
Bigtable首先通过块索引勉强加快了整个读取的速度: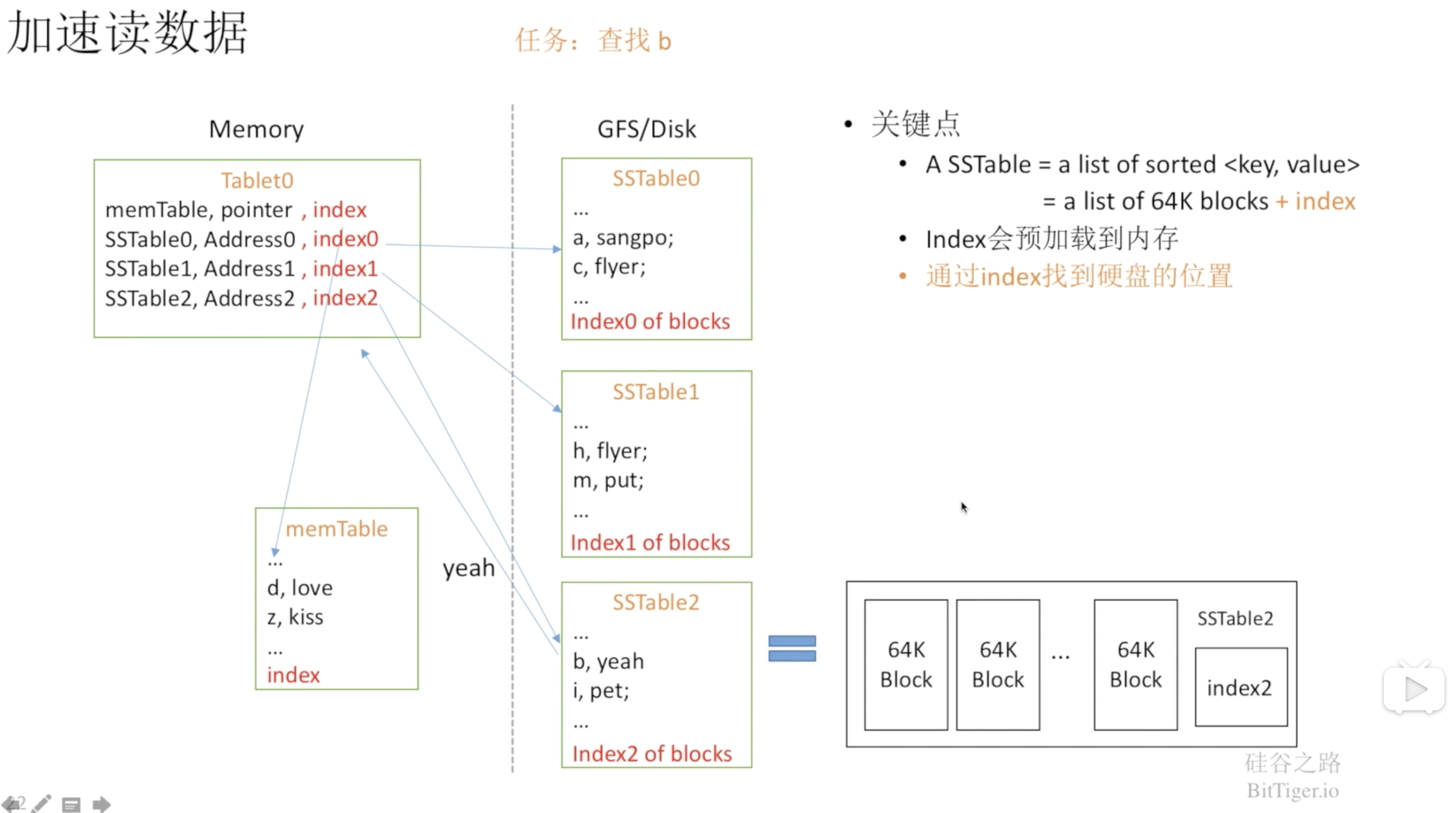
SSTable会把数据分成块进行存储,并在SSTable文件尾部保存块索引,块索引记录每个块结束的key及对应的offset。通过块索引,每次查找时先在内存中通过二分查找定位到SSTable中相应的数据块,然后进行一次磁盘访问,读取到块中的数据。
但即使有每个SSTable的索引,随着SSTable个数增多,读操作仍然很慢。即便有了合并操作,读操作仍然可能会访问大量的文件。因此,可以通过布隆过滤器将必然不存在我们想要查找的数据的SSTable给忽略: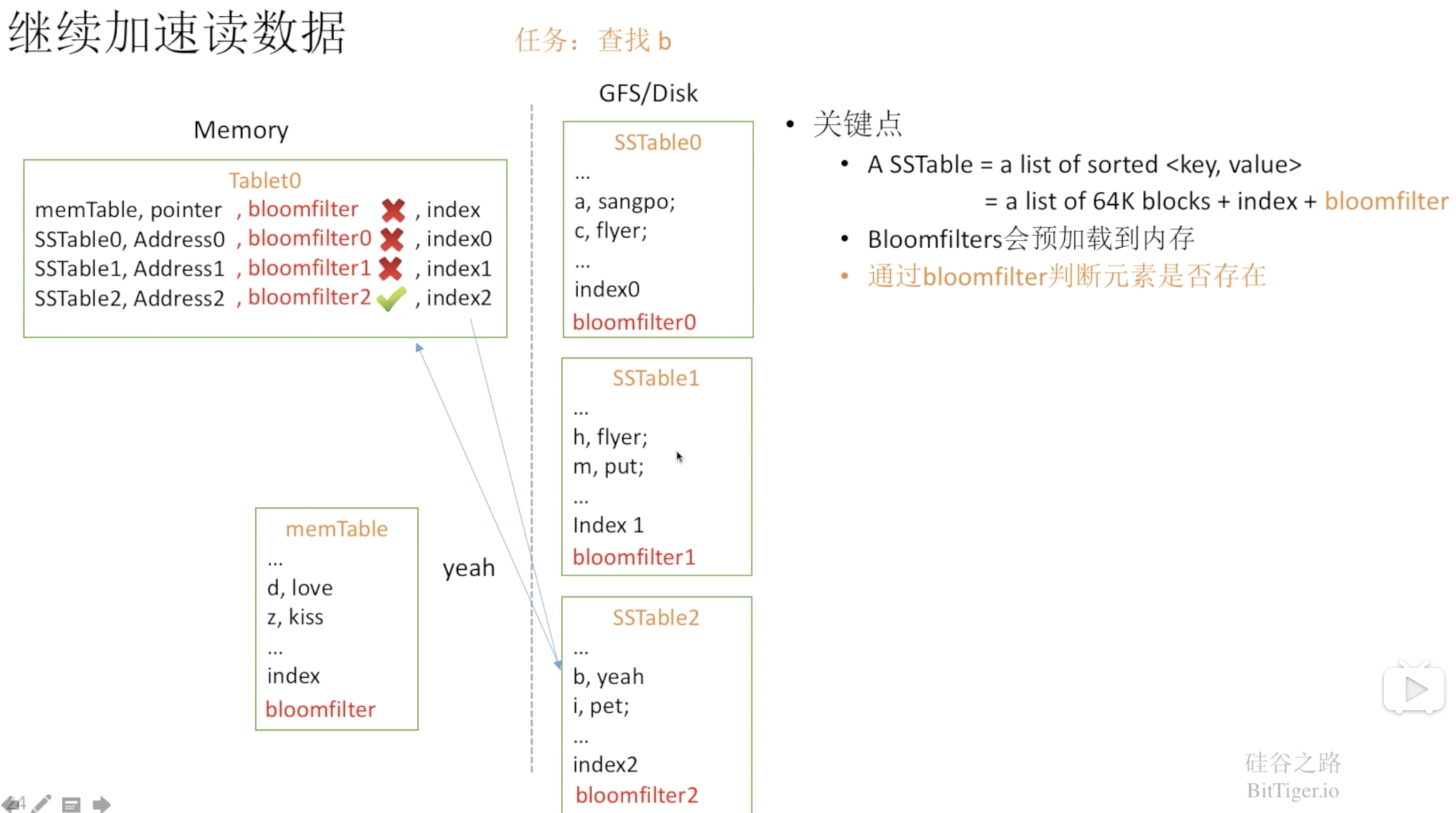
其实上面的memTable加上SSTables就是我们常说的LSM(Log Structured Merge Trees)。B+树和log追加型文件是数据读写的两个极端,B+树读效率高而写效率差,log追加型文件写效率高而读效率差。因此要在排序和log追加型文件之间做个折中,于是就引入了LSM模型,通过名称可以看出LSM既有日志型的文件操作,提升写效率,又在每个SSTable中排序,保证了查询效率。
细节
Tablet分配
Bigtable使用Chubby跟踪记录Tablet服务器的状态。当一个Tablet服务器启动时,它在Chubby的一个指定目录下建立一个有唯一性名字的文件,并且获取该文件的独占锁。Master服务器实时监控着这个目录,因此Master服务器能够知道有新的Tablet服务器加入了。如果Tablet服务器丢失了Chubby上的独占锁,比如由于网络断开导致Tablet服务器和Chubby的会话丢失,它就停止对Tablet提供服务。只要文件还存在,Tablet服务器就会试图重新获得对该文件的独占锁;如果文件不存在了,那么Tablet服务器就不能再提供服务了,它会自行退出。
Master服务器通过轮询Tablet服务器文件锁的状态来检测何时Tablet服务器不再为它的Tablet提供服务,此时Master服务器就会尝试获取该Tablet服务器文件的独占锁,如果成功获取到了,就说明Chubby是正常运行的,而Tablet可能是宕机了或者网络故障,此时Master服务器就删除该Tablet服务器在Chubby上的服务器文件以确保它不再给Tablet提供服务,一旦Tablet服务器在Chubby上的服务器文件被删除了,Master服务器就把之前分配给它的所有Tablet放入未分配的Tablet集合中。
压缩
- Minor Compaction:随着写请求的不断增多,memTable在内存中的空间不断增大,当memTable的大小达到一定阈值时,memTable被dump到GFS中成为不可变的SSTable。
- Merging Compaction:随着memTable不断的变为SSTable,SSTable也不断增多,意味着读操作需要读取的SSTable也越来越多,为了限制SSTable的个数,Tablet Server会在后台将多个SSTable合并为一个。
- Major Compaction:Major Compaction是一种特殊的Merging Compaction,只把所有的SSTable合并为一个SSTable,在非Major Compaction产生的SSTable中可能包含已经删除的数据,Major Compaction的过程会将这些数据真正的清除掉,避免这些数据浪费存储空间。
Locality Group
客户程序可以指定多个列族形成一个group,group单独存成一个sstable,将通常不会一起访问的列族分割成不同的group可以提高读取操作的效率,还可以将group设定为全部存储在内存中。
缓存
Tablet服务器使用二级缓存策略:
- 扫描缓存是第一级缓存,主要缓存Tablet服务器通过SSTable接口获取的Key-Value对,这对于经常要重复读取相同数据的应用程序来说非常有效。
- Block缓存是二级缓存,缓存的是从GFS读取的SSTable的Block,这对于经常要读取刚刚读过的数据附近的数据的应用程序来说非常有效。
合并日志
如果每个Tablet都生成自己的Commit日志,那么就会产生大量的文件,并且这些文件并行写入GFS会有大量的磁盘seek操作。因此,Bigtable实现为每个Tablet服务器一个Commit日志文件,这个日志文件中混合了对多个Tablet修改的日志记录。
这种公用日志的方式虽然提高了普通操作的性能,但是在恢复的时候就麻烦了。当一个Tablet服务器宕机时,它加载的Tablet将会被迁移到很多其它的Tablet服务器上,那些新的Tablet服务器要从原来的Tablet服务器的日志中提取修改操作进行恢复,每台新的Tablet服务器都要读取完整的日志文件然后只执行它需要恢复的Tablet的相关修改操作。对此的一个优化便是把日志分成64M的段在不同的Tablet服务器按照关键字进行并行排序,这样对同一个Tablet修改操作的日志记录就连续存放在了一起,此时只要一次磁盘seek操作再顺序读取即可。
SSTable不变性
当从SSTable读取数据的时候,我们不必对文件系统访问操作进行同步。menTable是唯一一个能被读和写操作同时访问的可变数据结构,我们对memTable采用copy-on-write机制,从而允许读写操作并行执行。