简介
Dynamo是Amazon实现的一个高可用键值存储系统。它主要是针对以下场景而设计的:
- 通过唯一的key对数据进行读写,且存储的内容一般较小。
- 不需要复杂的事务操作。
- 对延迟的要求十分严格。
- 假设环境是安全的,不需要考虑认证和鉴权等问题。
除此之外,Dynamo还有以下一些设计原则:
- 永远可写。
- 高可扩展性。
- 对称性、去中心化、点对点。
- 异构性。
分片算法
Dynamo使用基于一致性哈希的分片方案。初级的一致性哈希算法会导致数据倾斜问题,因此使用虚拟节点均衡了负载。但尽管如此,当一个节点加入或离开系统时,需要将一部分key range移交给别的节点,这时会扫描整个本地持久存储以过滤出所需的数据,并且Merkle tree也需要重新计算。
Dynamo最终使用的分片方案是将哈希环等分Q份,T个机器节点时,每个机器分得S个分片,其中Q=T*S。由于分片固定大小,可对应单个文件,因此容易加入或删除节点,且容易备份。
系统接口
Dynamo将数据复制到N台机器上(N是可配置的)。存储某个特定key的所有节点组成一个优先列表(为了容错,列表节点会大于N个),并且由于引入了虚拟节点,优先列表在选择节点的时候会跳过一些位置,以防止相同的物理节点。
Dynamo存储键值对象对接口非常简单,它提供两个操作:
get()put()
任何存储节点都可以接受任何key的get()和put()操作请求。为了保证副本的一致性,Dynamo使用了一种类似仲裁系统(quorum systems)的一致性协议,这个协议有两个配置参数:
- R:允许执行一次读操作所需的最少投票者
- W:允许执行一次写操作所需的最少投票者
其中,R + W > N(R或W至少有一个超过半数),只要R + W > N便可以保证客户端一定能读到最新版本的数据,因为这意味着R和W中至少有一个节点存在于交集之中(鸽笼原理)。
put()操作流程:当收到一个put()请求后,coordinator节点(必须是优先列表中的)会为新版本数据生成vector clock并将其保存到本地,然后将新版本数据发送给前N个健康节点,只要有至少W-1个节点返回成功,这次写操作就认为是成功了。
get()操作流程:对于一次get()请求,coordinator节点会向前N个健康节点请求这个key对应的数据,等到R个响应之后,就将结果返回给客户端。如果coordinator收到了这个数据的多个版本,就会将没有因果关系的所有版本都响应给客户端。
为了提高系统的可用性和持久性,Dynamo的仲裁机制是宽松的,即读写操作只需在优先列表的前N个健康节点上执行,而不一定非要是前N个节点。换句话说,当遇到不健康的节点时,会沿着一致性哈希环的顺时针方向顺延,将数据保存到一个临时节点的本地的一个独立数据库中,并且不断扫描原节点是否可用,一旦可用了就将这个数据归还,并将其从本地数据库中删除,这个过程就是Dynamo的Hinted Handoff。
还需要注意的是,每个节点都可以作为读请求的coordinator,而写请求的coordinator必须由key的优先列表里面的节点才能充当,因为优先列表中的节点被赋予了额外的职责:创建一个新的版本戳。
数据版本
Dynamo只提供最终一致性,所有更新操作会异步地传递给所有的副本,因此同一个数据可能会存在多个版本。
Dynamo使用vector clock来跟踪同一个对象不同版本之间的因果性,自动解决具有因果性的版本冲突,并且将不具有因果性的版本冲突交给应用层自行合并。一个vector clock分量就是一个(node, counter),通过列出数据在每个节点上的处理序列可以发现不同版本之间的因果关系,当某个vector clock的所有分量都小于另一个时,该vector clock便是另一个的因,可以被覆盖。
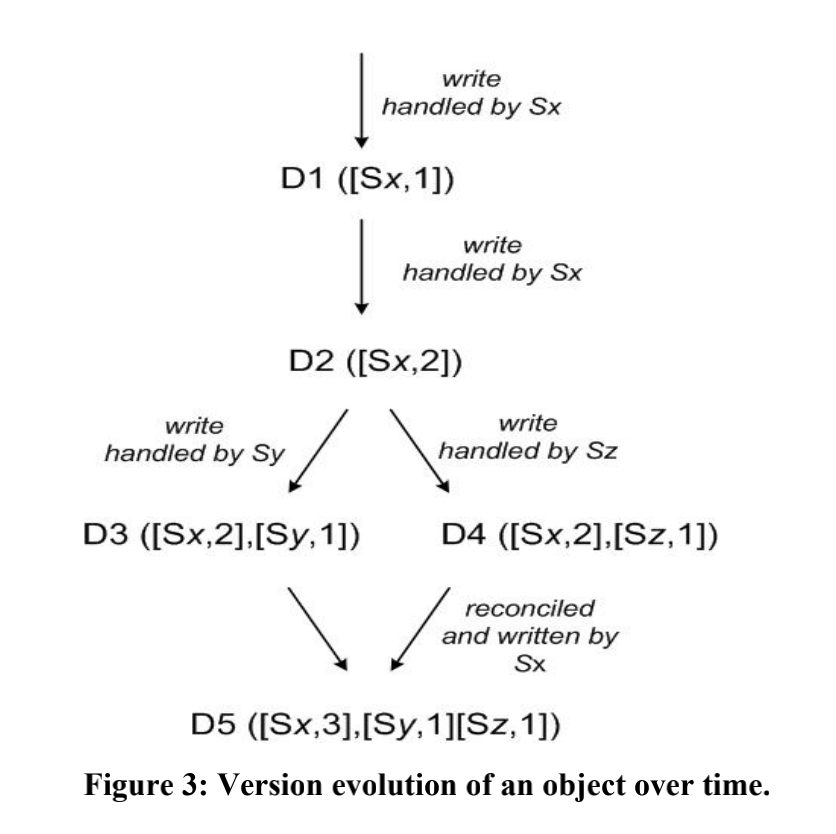
如上图所示,D1与D2是没有版本冲突的,D1是作为D2的因,因此可以用D2将D1数据直接给覆盖掉。但是D3和D4是并行分支的关系,系统没办法将其自动合并,所以这两个版本都会被保留并在读取时交给客户端,由客户端自己负责解决这个冲突,并将其写回。
同步恢复
上面介绍的Hinted Handoff机制在节点临时出现故障时提高了系统的可用性,但如果临时节点在归还数据前也故障了,那么需要有一种机制让原节点能与其它健康节点保持一致。因此,Dynamo实现了一种逆熵(副本同步)协议来保证副本之间数据的一致性。
Dynamo使用了Merkle tree通过仅发送不同的部分来减少数据传输量:
- 每一个分片维护一个Merkle Tree。
- 需要比较分片是否相同时,自根向下的比较两个Merkle Tree的对应节点,从而快速定位不同的部分。
关于Merkle tree在这篇博客中有很好的介绍:Merkle 树。
成员信息及故障检测
- 为了避免节点失效导致再平衡后又恢复,Dynamo加入或离开集群都需要手动通过命令完成;
- 当有用户请求时,coordinator会发现不可达的节点,并用其他节点代替之,之后开始周期性探测其恢复;
- Dynamo集群中的每台机器都会维护当前集群的成员及节点不可达等信息,这些信息通过gossip协议广播到整个集群;
- 客户端可以通过任意一个节点获得并维护这种成员信息,从而精确的找到自己要访问的数据所在。
添加/移除存储节点
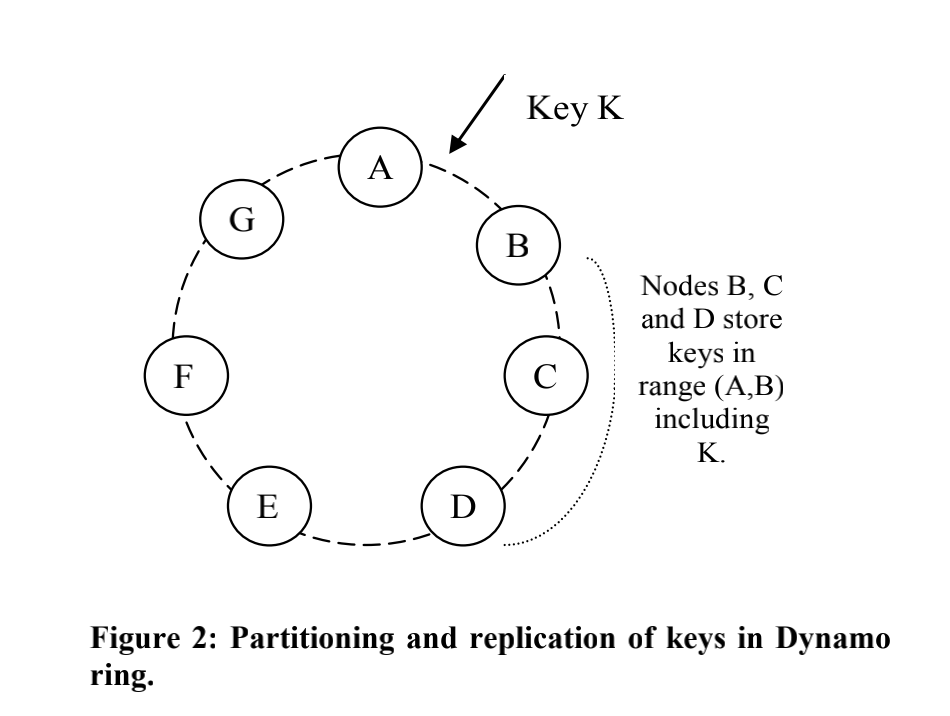
当一个新节点X加入到系统后,它会获得一些随机分散在哈希环上的token。对每个分配给X的key range,当前可能已经有一些节点在负责处理了。因此,将key range分配给X后,这些节点就不需要处理这些key对应的请求了,而要将keys转给X。
考虑一个简单的情况:X加入下图中A和B之间。这样,X就负责处理落到 (F, G], (G, A] 和 (A, X] 之间的key。结果,B、C和D节点就不需要负责相应range了。因此,在收到X的转移key请求之后,B、C和D会向X转移相应的key。当移除一个节点时,key重新分配的顺序和刚才相反。